LLM 指令微调方法
介绍
经过无监督预训练的模型已经具备基本的语言理解能力,也就是说,给它输入一段不完整的文本,它能够比较准确的预测下一个词是什么,但也仅此而已。此时的模型遵循指令的能力还很弱,也基本没有什么对话能力,在早期的 GPT3 时代,让模型完成一些任务的方法是构造一个相对特殊的 prompt,比如让它写一个新闻
Title: United Methodists Agree to Historic Split
Subtitle: Those who oppose gay marriage will form their own denomination
Article:
这里的 Article: 表明了这是一个还没有完成的文本,如果模型理解了前面的内容,那么就该知道接下来应该生成什么。
受到这种方法的启发,后期的模型在完成了预训练之后,一般会再使用特定格式的 prompt 来对模型进一步训练,从而增强模型在这种格式输入下的表现,比如 alpaca 项目中的指令模板
Below is an instruction that describes a task. Write a response that appropriately completes the request
### Instruction:
{instruction}
### Response:
以及 vicuna 项目中的指令模板
A chat between a curious user and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the user's questions.
### Human: {instruction}
### ASSISTANT:
让模型适应固定指令格式的训练阶段就叫做指令微调(instruction tuning),通过这种方式训练,模型可以更准确的理解用户的意图,从而给出生成更合理的回复。
当然,后来各家模型都遵循 OpenAI 的调用规范,使用 role 和 content 来表示对话的角色和内容,比如
messages=[
{"role": "user", "content": "Hello"},
{"role": "assistant", "content": "Hello, how are you?"},
{"role": "user", "content": "I'm fine, thanks, and you?"},
]
然后再使用自家的格式化规范来生成 prompt,比如 gemma 模型的格式化结果
<bos><start_of_turn>user
hello<end_of_turn>
<start_of_turn>model
hello, how are you?<end_of_turn>
<start_of_turn>user
i'm fine, thanks, and you?<end_of_turn>
由于这种规范实在太好用,所以 huggingface 也在 transformers 的 Tokenizer 中提供了 apply_chat_template 方法,可以直接将对话内容格式化
tokenizer.apply_chat_template(messages, tokenize=False)
数据集处理
微调阶段的数据集一般都是有监督数据,也就是说,数据集中的每个样本都有一个 context 序列和一个 label 序列,我们的训练目标就是让模型的输出尽可能接近 label 序列。无论原始的数据格式是怎样的,我们都需要将每个样本转换成如下所示的序列格式
| context | label |
o o o o o o x x x x x x x
以 alpaca 数据集为例,它的样本格式如下:
{
"instruction": "Give three tips for staying healthy.",
"input": "",
"output": "1. Eat a balanced and nutritious diet: Make sure your meals are inclusive of a variety of fruits and vegetables, lean protein, whole grains, and healthy fats. This helps to provide your body with the essential nutrients to function at its best and can help prevent chronic diseases.\n\n2. Engage in regular physical activity: Exercise is crucial for maintaining strong bones, muscles, and cardiovascular health. Aim for at least 150 minutes of moderate aerobic exercise or 75 minutes of vigorous exercise each week.\n\n3. Get enough sleep: Getting enough quality sleep is crucial for physical and mental well-being. It helps to regulate mood, improve cognitive function, and supports healthy growth and immune function. Aim for 7-9 hours of sleep each night."
}
其中 instruction 和 input 共同构成 context,output 构成 label,利用 transformers tokenizer的 apply_chat_template 方法,我们可以将这个样本进行转换
def generate_text(sample: dict):
if "input" in sample:
prompt = f"""Below is an instruction that describes a task. Write a response that appropriately completes the request.
{sample["instruction"]}. Here are the inputs: {sample["input"]}"""
else:
prompt = f"""Below is an instruction that describes a task. Write a response that appropriately completes the request.
{sample["instruction"]}."""
messages = [
{"role": "user", "content": prompt},
{"role": "assistant", "content": sample["output"]}
]
text = tokenizer.apply_chat_template(messages, tokenize=False)
return text
如果 tokenizer 本身没有 chat_template(这在比较新的模型上不太常见),那么我们可以自己设置一个
tokenizer.chat_template = ""
这里的表达式是 jinja2 模板语言,更详细的信息可以参考 transformers 的官方文档。利用上述模板,我们可以将样本格式化为
<|im_start|>user
Below is an instruction that describes a task. Write a response that appropriately completes the request.
Give three tips for staying healthy.. Here are the inputs: <|im_end|>
<|im_start|>assistant
1. Eat a balanced and nutritious diet: Make sure your meals are inclusive of a variety of fruits and vegetables, lean protein, whole grains, and healthy fats. This helps to provide your body with the essential nutrients to function at its best and can help prevent chronic diseases.
2. Engage in regular physical activity: Exercise is crucial for maintaining strong bones, muscles, and cardiovascular health. Aim for at least 150 minutes of moderate aerobic exercise or 75 minutes of vigorous exercise each week.
3. Get enough sleep: Getting enough quality sleep is crucial for physical and mental well-being. It helps to regulate mood, improve cognitive function, and supports healthy growth and immune function. Aim for 7-9 hours of sleep each night.<|im_end|>
这里 <|im_start|>assistant 以及前面的部分就是 context 序列,后面的部分就是 label 序列,当然,不同 chat_template 的标志符号不同。
接下来我们就需要对整个序列进行 tokenization
tokenizer.encode(text, return_tensors="pt", max_length = 1024, truncation=True)
然后构造成 batch,但是这里存在几种不同的路线选择。我们知道 batch 里面每个样本张量的维度必须是一样的,如果样本 token 序列的长度不同,需要把不足的部分填充,也就是常说的 padding,比如下面给出的例子
x x x x x x x o o o o o o o o * * *
x x x x x x x x x x o o o o o o o o
x x x x o o o o o o o o o o * * * *
其中 * 就是 padding 的部分。一般常规的方法就是这样了,但是显然,填充的部分消耗了计算量,却没有在计算损失的时候提供任何贡献,因此这是一种低效的做法。更加高效的做法是类似于预训练阶段的数据处理方式,把所有文本序列拼接在一起,然后按照一定的 max_length 和 batch_size 对 token 序列进行切分,这样就可以避免填充的问题了,这种方式也叫 packed,生成的 batch 类似下面这样
x x x x x x x o o o o o o o o x x x
x x x x x x x o o o o o o o o x x x
x o o o o o o o o o o
但是这样做有一个明显的缺陷,就是在切分的时候,可能会把一个样本的 context 和 label 切分到两个 tensor 中,并且指令模板的特殊字符也不一定在 tensor 的开头或结尾。后面我们将会看到这对训练稍微有点负面影响。
最后一种解决方案在 max_length 限制下,尽可能多的拼接样本序列,使得 padding 数量尽量少,并且不对序列进行切分,这样可以保证每个样本的 context 和 label 都在同一个 tensor 中,我把这种方式称为 concat。
损失函数
这一节涉及原理性的内容,和具体的代码关系不大,如果不感兴趣可以跳过。
自回归语言模型的预测模式是给定一个上下文 token 序列,预测下一个 token 的分布,然后对这个分布进行采样后将新的 token 拼接到原序列后面,继续预测下一个 token 分布,直到达到最大序列长度或者得到终止 token。设上下文 token 序列符号表示为 $x_1, x_2,…,x_c$,那么自回归语言模型的推理过程本质上是在不断计算下列条件分布
\[\begin{aligned} &p(x_{c+1} \mid x_1, x_2,...,x_c)\\ &p(x_{c+2} \mid x_1, x_2,...,x_{c+1})\\ &\cdots\\ &p(x_{c+k} \mid x_1, x_2,...,x_{c+k-1})\\ \end{aligned}\]其中 $k$ 表示 label token 序列长度。我们可以将 label token 序列的联合分布关于上下文序列的条件概率表示为
\[p(x_{label}\mid x_{ctx};\theta)\]其中 $x_{label}$ 表示 label token 序列随机变量,$x_{ctx}$ 表示上下文 token 序列随机变量,$\theta$ 表示模型参数。在真实样本条件下,对于未知的模型参数,我们可以得到似然函数
\[\mathcal{L}(\theta) = p(x_{label} = X_{label} \mid x_{ctx} = X_{ctx}; \theta)\]这里的 $X_{label}$ 和 $X_{ctx}$ 表示 label token 序列和上下文 token 序列,即 $(X_{ctx}, X_{label})$ 是一个训练样本。
利用贝叶斯公式,我们可以将上述似然函数变换为(注意这里我们为了简化推导,省略了 $\theta$)
\[\begin{aligned} \mathcal{L}(\theta) &= p(label\mid ctx) \\&= p(x_{c+1}, x_{c+2},...,x_{c+k} \mid x_1, x_2,...,x_c) \\ &= p(x_{c+2},...,x_{c+k} \mid x_1, x_2,..., x_{c+1}) p(x_{c+1} \mid x_1, x_2,...,x_c)\\ &= p(x_{c+3},...,x_{c+k} \mid x_1, x_2,..., x_{c+2}) p(x_{c+2} \mid x_1, x_2,...,x_c, x_{c+1}) p(x_{c+1} \mid x_1, x_2,...,x_c)\\ &= p(x_{c+4},...,x_{c+k} \mid x_1, x_2,...,x_{x+3}) \prod_{i=1}^{3} p(x_{c+i} \mid x_1, x_2,...,x_{c+i-1}) \\ &\cdots\\ &= p(x_{c+k}\mid x_1, x_2,...,x_{c+k-1}) \prod_{i=1}^{k-1} p(x_{c+i} \mid x_1, x_2,...,x_{c+i-1})\\ &= \prod_{i=1}^k p(x_{c+i} \mid x_1, x_2,...,x_{c+i-1}) \end{aligned}\]显然,为了获得最佳的语言模型参数,我们需要最大化似然函数,即
\[\theta^{best} = \arg \max_{\theta} \mathcal{L}(\theta)\]而为了简化计算,我们通常会取似然函数的对数形式,即
\[\log(\mathcal{L}(\theta)) = \sum_{i=1}^k \log(p(x_{c+i} \mid x_1, x_2,...,x_{c+i-1};\theta))\]对于损失函数来讲,根据其定义,我们可以为上式添加一个负号,使得计算目标为损失函数最小化,所以自回归语言模型的损失函数就是负对数似然函数。
至于为什么在实际代码中优化目标函数一般是交叉熵,简单来说,当语言模型同时满足平稳性和遍历性条件时,模型输出与标签之间的交叉熵为(具体可以参考这篇文章)
\[H(\eta, \xi) = \lim_{n \to \infty} -\frac{1}{n} \sum_{i=1}^n \log p_{\xi}(X_{i} \mid X_{\lt i})\]可以看到上述交叉熵的公式与负对数似然函数只差了一个系数 $ \frac 1 n $,原因在于交叉熵在整个样本集上取得平均,而我们推导的负对数似然函数只是针对单个样本的,所以两者实际上是等价的。但值得注意的是,在 PyTorch 实现中,torch.nn.functional 模块下的 cross_entroy 和 nll_loss 这两个函数,cross_entropy 会自动对输入进行 softmax 操作,而 nll_loss 不会,也就是说 cross_entroy 的输入是未归一化的 logits,而 nll_loss 的输入是已经归一化的概率分布。下面这个例子应该能说明情况
import torch
import torch.nn.functional as F
logits = torch.randn(1, 10, 100)
probs = F.softmax(logits, dim=-1)
labels = torch.randint(0, 100, (1, 10))
print(F.cross_entropy(logits.view(-1, 100), labels.view(-1)))
print(F.nll_loss(torch.log(probs.view(-1, 100)), labels.view(-1)))
代码实现
接下来我们以 GPT2 为例,使用 alpaca 数据集进行指令微调,让原本只能进行文本补全的 GPT2 模型具备回答问题的能力。之所以选择 GPT2 是因为,首先它是一个比较小巧的模型,最小的版本只有 270M 参数,可以在一般的笔记本上训练,另外它的预训练模型没有指令模板,方便展示对其赋予指令理解能力的过程。
设置 chat_format
在近期版本的 transformers 框架中,为了解决不同模型的指令格式不同的问题,统一为模型提供了 apply_chat_format 接口,可以将对话内容格式化到模型能识别的指令形式。由于 GPT2 模型没有经过指令微调,所以我们需要自己设置一个 chat_format,这里借鉴 trl 框架的 https://github.com/huggingface/trl/blob/main/trl/models/utils.py 文件中的代码并进行简化
from typing import Tuple
from dataclasses import dataclass
from trl.models.utils import ChatMlSpecialTokens
from transformers import PreTrainedModel, PreTrainedTokenizer
def setup_chat_format(
model: PreTrainedModel,
tokenizer: PreTrainedTokenizer,
resize_to_multiple_of: int = None,
) -> Tuple[PreTrainedModel, PreTrainedTokenizer]:
"""
Setup chat format by adding special tokens to the tokenizer, setting the correct format, and extending the embedding layer of the model based on the new special tokens.
Args:
model (`~transformers.PreTrainedModel`): The model to be modified.
tokenizer (`~transformers.PreTrainedTokenizer`): The tokenizer to be modified.
Returns:
model (`~transformers.PreTrainedModel`): The modified model.
tokenizer (`~transformers.PreTrainedTokenizer`): The modified tokenizer.
"""
# check if format available and retrieve
chat_format = ChatMlSpecialTokens()
# set special tokens and them
tokenizer.eos_token = chat_format.eos_token
tokenizer.pad_token = chat_format.pad_token
tokenizer.bos_token = chat_format.bos_token
tokenizer.add_special_tokens({"additional_special_tokens": [chat_format.bos_token, chat_format.eos_token]})
# set chat format for tokenizer
tokenizer.chat_template = chat_format.chat_template
# resize embedding layer to a multiple of 64, https://x.com/karpathy/status/1621578354024677377
model.resize_token_embeddings(
len(tokenizer), pad_to_multiple_of=resize_to_multiple_of if resize_to_multiple_of is not None else None
)
# Update the model config to use the new eos & bos tokens
if getattr(model, "config", None) is not None:
model.config.pad_token_id = tokenizer.pad_token_id
model.config.bos_token_id = tokenizer.bos_token_id
model.config.eos_token_id = tokenizer.eos_token_id
# Update the generation config to use the new eos & bos token
if getattr(model, "generation_config", None) is not None:
model.generation_config.bos_token_id = tokenizer.bos_token_id
model.generation_config.eos_token_id = tokenizer.eos_token_id
model.generation_config.pad_token_id = tokenizer.pad_token_id
return model, tokenizer
这里的 ChatMlSpecialTokens 就是 huggingface 推荐的通用 chat_format。使用 setup_chat_format 函数可以对模型和 tokenizer 进行统一修改,主要就是为 tokenizer 添加了两个特殊的 token,即 <|im_start|> 和 <|im_end|>,对应的需要增加模型的 embedding layer 大小。其中 resize_to_multiple_of 参数来自于 karpathy 的一个想法,他提到可以把模型的 embedding layer 大小调整到 64 的倍数,这样可以提高计算效率,我们暂时先不管这个,感兴趣的同学可以研究研究。
数据集
首先定义函数对数据样本进行格式化,这里假设每个样本都有 instruction 和 output 两个字段,input 字段可选,符合 alpaca 数据集的格式
def alpaca_formatting_func(sample: dict, tokenizer: AutoTokenizer):
"""
:param sample:
{
"instruction": str,
"input": str,
"output": str
}
"""
if "input" in sample and sample["input"] != "":
prompt = f"""Below is an instruction that describes a task. Write a response that appropriately completes the request.
{sample["instruction"]}. Here are the inputs: {sample["input"]}"""
else:
prompt = f"""Below is an instruction that describes a task. Write a response that appropriately completes the request.
{sample["instruction"]}"""
messages = [
{"role": "user", "content": prompt},
{"role": "assistant", "content": sample["output"]}
]
text = tokenizer.apply_chat_template(messages, tokenize=False)
return text
然后定义函数对数据集进行 tokenize
def tokenize_dataset(samples: Iterable[Any],
tokenizer: AutoTokenizer,
formating_func: Callable,
max_length: int = -1,
add_special_tokens: bool = False):
texts = [formating_func(sample) for sample in samples]
loop = tqdm(enumerate(texts), total=len(texts))
loop.set_description("Tokenizing")
encodings = []
for _, text in loop:
if max_length > 0:
encoding = tokenizer.encode(text, return_tensors="pt", max_length=max_length, truncation=True, add_special_tokens=add_special_tokens) \
.squeeze()
else:
encoding = tokenizer.encode(text, return_tensors="pt", add_special_tokens=add_special_tokens) \
.squeeze()
encodings.append(encoding)
return encodings
接下来我们定义前面提到的三种批量化方式,也就是 padding, packed 和 concat 模式。
def padding_handler(encodings: List[torch.Tensor]):
return encodings
def packed_handler(encodings: List[torch.Tensor], max_length: int):
## concatenate
encoding = torch.cat(encodings, dim=0)
## split
encodings = []
for i in range(0, encoding.size(0), max_length):
encodings.append(encoding[i:i+max_length])
return encodings
def concat_handler(encodings: List[torch.Tensor], max_length: int):
## sort by length
encodings = sorted(encodings, key=lambda x: x.shape[0], reverse=True)
encodings_concated = []
i = 0
j = len(encodings) - 1
current = encodings[i]
while i < j:
right_one = encodings[j]
if current.shape[0] + right_one.shape[0] <= max_length:
current = torch.cat([current, right_one], dim=0)
j -= 1
else:
encodings_concated.append(current)
i += 1
current = encodings[i]
encodings_concated.append(current)
encodings = encodings_concated
其中 padding 模式直接返回原始的编码序列,后面将我们使用其他工具执行具体的 pad 操作,packed 模式将所有样本序列拼接在一起,然后按照 max_length 进行切分,concat 模式则首先将编码序列按长度从大到小排列,然后从两个方向搜索,尽量让长序列和短序列拼接在一起,这样可以尽量减少总的序列数量,拼接后的序列可能会缺一些数据,之后再执行 pad 操作补全。
然后我们再定义数据集类,注意这里在 packed 模式下,我们没有对 token 序列的长度进行限制,因为后面会按照 max_length 进行切分,所以有可能出现 packed 模式比 padding 和 concat 模式的 token 数量更多的情况。
class GeneralDataset(Dataset):
def __init__(self,
samples: List[Dict[str, str]],
tokenizer: AutoTokenizer,
formating_func: callable,
max_length: int,
mode: str = "padding",
add_special_tokens: bool = False):
if mode == "packed":
encodings = tokenize_dataset(samples, tokenizer, formating_func, -1, add_special_tokens)
encodings = packed_handler(encodings, max_length)
else:
encodings = tokenize_dataset(samples, tokenizer, formating_func, max_length, add_special_tokens)
if mode == "concat":
encodings = concat_handler(encodings, max_length)
elif mode == "padding":
encodings = padding_handler(encodings)
else:
raise ValueError("Invalid mode: {}".format(mode))
inputs = []
for encoding in encodings:
inputs.append({
"input_ids": encoding,
"attention_mask": torch.ones_like(encoding)
})
self.inputs = inputs
def __len__(self):
return len(self.inputs)
def __getitem__(self, idx):
return self.inputs[idx]
完成数据集的定义后,我们使用 transformers 的 DataCollatorForLanguageModeling 作为 batch data collator,这个类会自动对数据进行 padding 操作。
data_collator = DataCollatorForLanguageModeling(tokenizer=tokenizer, mlm=False)
trainloader = DataLoader(trainset, batch_size=batch_size, shuffle=False, collate_fn=data_collator)
valloader = DataLoader(valset, batch_size=batch_size, shuffle=False, collate_fn=data_collator)
训练过程
首先,我们引入 package,并设置参数如下
import torch
from torch.optim import AdamW
import torch.nn.functional as F
from tqdm import tqdm
from torch.utils.data import DataLoader
from transformers import AutoModelForCausalLM, AutoTokenizer, get_linear_schedule_with_warmup
from transformers.data import DataCollatorForLanguageModeling
from tensorboardX import SummaryWriter
from datasets import load_dataset
epoch=100
max_steps = 10000
save_step = 300
batch_size=16
learning_rate = 1e-4
warmup_steps = 1000
eps = 1e-8
context_length = 256
mode = "padding"
train_split_ratio = 0.9
这里我们让 epoch 足够大,也就是说数据集可以反复训练,直到到达 max_steps 为止,训练过程中我们可以通过验证集来判断模型是否过拟合。然后初始化模型和 tokenizer 以及数据加载器
device = "cuda:0"
save_dir = "./sft"
model_path = "gpt2"
model = AutoModelForCausalLM.from_pretrained(model_path, device_map = {"": device})
tokenizer = AutoTokenizer.from_pretrained(model_path)
model, tokenizer = setup_chat_format(model, tokenizer)
model.to(device)
samples = load_dataset("yahma/alpaca-cleaned", "default", split="train")
def formatting_func(examples):
return alpaca_formatting_func(examples, tokenizer)
train_samples = samples.select(range(int(len(samples) * train_split_ratio)))
val_samples = samples.select(range(int(len(samples) * train_split_ratio), len(samples)))
trainset = GeneralDataset(train_samples, tokenizer, formatting_func, context_length, mode=mode, add_special_tokens=False)
valset = GeneralDataset(val_samples, tokenizer, formatting_func, context_length, mode="padding", add_special_tokens=False)
data_collator = DataCollatorForLanguageModeling(tokenizer=tokenizer, mlm=False)
trainloader = DataLoader(trainset, batch_size=batch_size, shuffle=False, collate_fn=data_collator)
valloader = DataLoader(valset, batch_size=batch_size, shuffle=False, collate_fn=data_collator)
注意这里我们始终使用 padding 模式对验证集进行处理,因为我们需要保证验证集对每个模型都是一样的。再定义优化器等组件
optimizer = AdamW(model.parameters(), lr=learning_rate, eps=eps)
scheduler = get_linear_schedule_with_warmup(optimizer, num_warmup_steps=warmup_steps, num_training_steps=max_steps)
scaler = torch.cuda.amp.GradScaler()
writer = SummaryWriter()
其中 scaler 用来进行混合精度训练,writer 用来记录训练过程的指标数据。
下面我们再定义验证函数
def val(step: int, model, valloader):
model.eval()
loop = tqdm(enumerate(valloader), total=len(valloader), leave=False)
val_total_loss = 0
loop.set_description("Validation")
for i, batch in loop:
input_ids = batch["input_ids"].to(device)
attention_mask = batch["attention_mask"].to(device)
labels = input_ids.clone()
## set label id to -100 where attention mask is 0
labels[attention_mask == 0] = -100
with torch.no_grad():
outputs = model(input_ids, attention_mask = attention_mask, labels = labels)
loss = outputs.loss
val_total_loss += loss.item()
print(f"Step {step} Validation loss: ", val_total_loss/len(valloader))
return val_total_loss / len(valloader)
以及训练函数
def train_epoch(epoch, step, model, trainloader, valloader, optimizer, scheduler):
model.train()
loop = tqdm(enumerate(trainloader), total=len(trainloader), leave=False)
train_total_loss = 0
best_val = (0, 1e9)
for i, batch in loop:
step += 1
input_ids = batch["input_ids"].to(device)
attention_mask = batch["attention_mask"].to(device)
labels = input_ids.clone()
## set label id to -100 where attention mask is 0
labels[attention_mask == 0] = -100
optimizer.zero_grad()
with torch.cuda.amp.autocast(dtype=torch.float16, enabled=True):
outputs = model(input_ids, attention_mask = attention_mask, labels = labels)
loss = outputs.loss
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()
scheduler.step()
train_total_loss += loss.item()
loop.set_description(f"Epoch {epoch}|Step {step} - loss: {(train_total_loss/(i+1)):.4f}")
if (i+1) % save_step == 0 or step >= max_steps:
writer.add_scalar("Loss/train", train_total_loss/(i+1), step+1)
writer.add_scalar("learning_rate", scheduler.get_last_lr()[0], step+1)
val_loss = val(epoch, model, valloader)
writer.add_scalar("Loss/val", val_loss, step+1)
if val_loss < best_val[1]:
best_val = (step, val_loss)
model.save_pretrained(f"{save_dir}/gpt2-{mode}-best")
tokenizer.save_pretrained(f"{save_dir}/gpt2-{mode}-best")
model.train()
if step >= max_steps:
print("Max steps reached")
exit(0)
val_loss = val(epoch, model, valloader)
if val_loss < best_val[1]:
best_val = (step, val_loss)
model.save_pretrained(f"{save_dir}/gpt2-{mode}-best")
tokenizer.save_pretrained(f"{save_dir}/gpt2-{mode}-best")
注意,这里我们将 attention_mask 等于 0 的位置上的 labels 数据设为 -100(也就是padding的位置),这样在模型内部计算交叉熵损失的时候会忽略这些位置上的值。最后启动训练
if __name__ == "__main__":
step = 0
for epoch in range(epoch):
train_epoch(epoch, step, model, trainloader, valloader, optimizer, scheduler)
step = len(trainloader) * (epoch+1)
writer.close()
结果分析
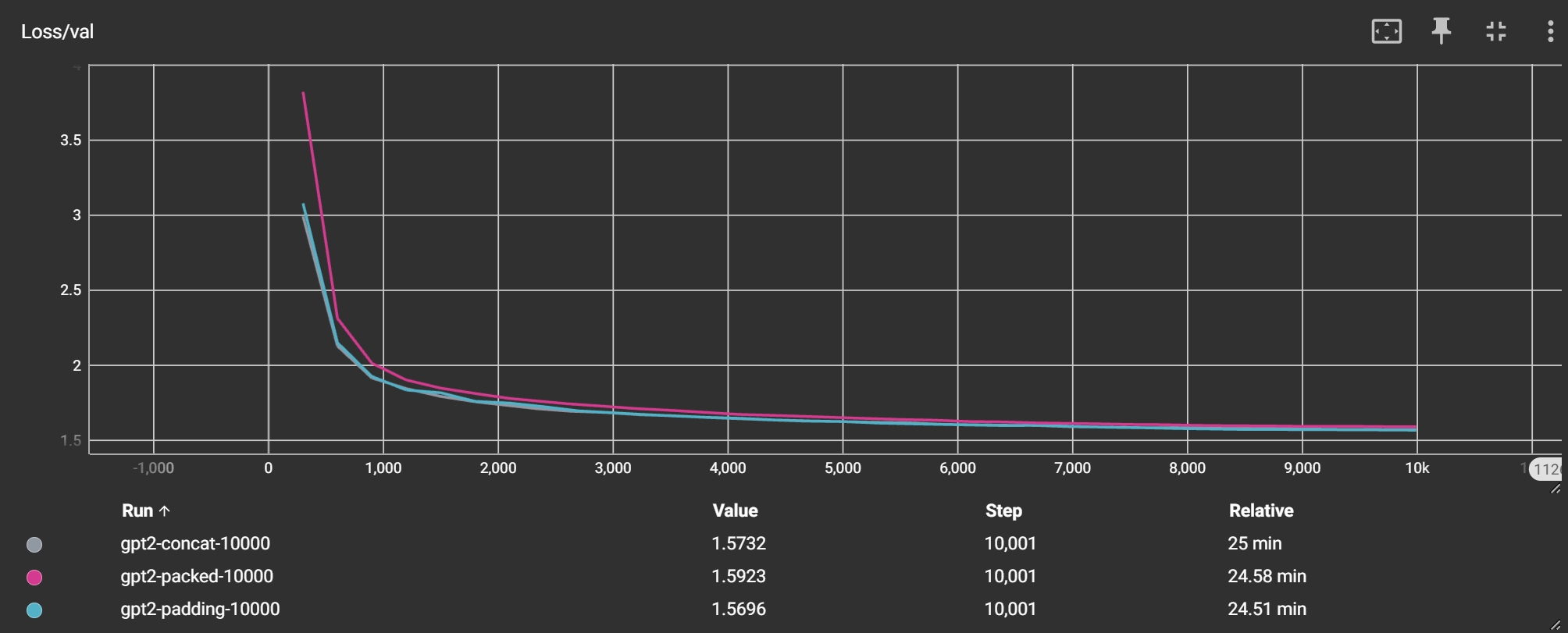
上图展示了三种数据处理方式的验证集损失曲线,可以看到,从指标上来看,使用 padding 和 concat 模式的效果类似,而 packed 模式的最终损失函数要稍微大一点,这也比较符合我们的预期。
然后我们再使用训练集中的数据对模型进行测试,比较三种数据处理方式的效果,以下为提示词
<|im_start|>user
Below is an instruction that describes a task. Write a response that appropriately completes the request.
Give three tips for staying healthy.<|im_end|>
<|im_start|>assistant
生成结果如下
| padding | concat | packed |
|---|---|---|
| 1. Eat a balanced diet: Eating a balanced diet is essential for maintaining good health. Here are three tips to help you stay healthy:\n\n1. Exercise regularly: Regular physical activity can help you burn calories and improve your mood. Aim for at least 150 minutes of moderate-intensity aerobic activity per week.\n\n2. Get enough sleep: Lack of sleep can lead to weight gain and can contribute to a host of health problems. Aim for at least 7-8 hours of sleep per night.\n\n3. Get enough rest: Lack of rest can lead to feelings of fatigue and a feeling of being overwhelmed. Aim for at least 7-8 hours of rest per night. | 1. Eat a balanced diet: Eating a balanced diet is essential for maintaining good health. Aim for a variety of foods, including fruits, vegetables, whole grains, lean proteins, and healthy fats. \n\n2. Exercise regularly: Regular physical activity can help improve your overall health. Aim for at least 150 minutes of moderate-intensity aerobic activity per week, and try to engage in at least 150 minutes of vigorous-intensity aerobic activity per week.\n\n3. Get enough sleep: Getting enough sleep is essential for overall health. Aim for at least 7-8 hours of sleep per night, and try to get at least 7-8 hours of rest each night. This will help you feel more rested and energized. | 1. Eat a balanced diet: Eating a balanced diet is essential for maintaining good health. Aim for at least 150 calories per day, and limit processed foods, sugary drinks, and processed foods.\n\n2. Get enough sleep: Sleep is essential for overall health. Aim for at least 7-9 hours of sleep per night, and limit caffeine and nicotine use.\n\n3. Get enough exercise: Regular physical activity can help improve your mood and reduce stress. Aim for at least 30 minutes of moderate-intensity aerobic activity per week, and limit caffeine and nicotine use. |
可以看到三者生成的结果都是合理的,也就是说我们的微调模型能够识别指令并生成回答。再测试一下训练集以外的指令:
<|im_start|>user
Below is an instruction that describes a task. Write a response that appropriately completes the request.
Can you tell me the history of Earth<|im_end|>
<|im_start|>assistant
生成结果如下
| padding | concat | packed |
|---|---|---|
| The Earth is a large, rotating body of water that is formed by the rotation of the Earth’s axis. It is the largest planet in the solar system and is the only one that orbits the Sun. It is the only planet in the solar system that has a temperature of around -40°C (212°F).\n\nThe Earth’s rotation is caused by the rotation of the Earth’s axis, which is caused by the force of gravity. The Earth’s rotation is caused by the force of gravity, which is the force of attraction between two objects. The Earth’s rotation is caused by the rotation of the Earth’s surface, which is caused by the force of gravity. The Earth’s rotation is caused by the force of gravity, which is the force of attraction between two objects. | The Earth is a large, rotating body of water that is formed by the rotation of the Earth’s axis. It is the largest planet in the solar system and is the only one that orbits the Sun. The Earth’s rotation is known as the Earth’s rotation, and it is the longest known cycle in the solar system.\n\nThe Earth’s rotation is caused by the rotation of the Earth’s axis, which is the force that pulls the Earth’s rotation around the Sun. The Earth’s rotation is caused by the rotation of the Earth’s surface, which is the force that pulls the Earth’s surface towards the Sun. The Earth’s rotation is caused by the rotation of the Earth’s atmosphere, which is the pressure that keeps the Earth’s surface warm.\n\nThe Earth’s rotation is caused by the rotation of the Earth’s magnetic field, which is the force that pulls the Earth’s magnetic field towards the Sun. The Earth’s rotation is caused by the rotation of the Earth’s magnetic field, which is the force that pulls the Earth’s magnetic | The Earth is a large, flat, and spherical planet with a diameter of approximately 4.5 billion kilometers. It is the largest planet in the solar system and is the only one that has a solid core. The Earth is the only planet in the solar system that has a liquid core, and its temperature is about the same as that of the sun.\n\nThe Earth is the only planet in the solar system that has a liquid core, and its temperature is about the same as that of the sun. |
虽然大量事实性错误很难崩,但是可以看到模型同样遵循了我们的指令。最后我们再使用 lm-evaluation-harness 框架评估模型在 hellaswag 数据集上的指标,检查指令微调是否把模型原本的能力破坏了。
lm-eval --model hf --model_args pretrained=./sft/gpt2-padding-best --task hellaswag
结果如下
| model | hellaswag/acc_norm |
|---|---|
| gpt2 | 0.3114 |
| padding | 0.3125 |
| concat | 0.3116 |
| packed | 0.3138 |
可以看到,本次微调没有破坏模型原有的能力,甚至还有提升,说明我们的微调是有效的。
总结一下,通过指令微调,我们使 GPT2 的预训练模型可以实现对话形式的生成任务,在微调过程中发现三种数据集的处理方式产生的结果差异不是很大,可能需要更多的实验来验证这一点。
参考链接
-
https://adithyask.medium.com/a-beginners-guide-to-fine-tuning-gemma-0444d46d821c
-
https://wandb.ai/capecape/alpaca_ft/reports/How-to-Fine-Tune-an-LLM-Part-1-Preparing-a-Dataset-for-Instruction-Tuning–Vmlldzo1NTcxNzE2
-
https://huggingface.co/docs/transformers/main/en/chat_templating
-
https://debuggercafe.com/instruction-tuning-gpt2-on-alpaca-dataset/