如何解释 top_p 和 temperature 参数对 LLM 生成多样性的影响
总所周知,在调用 LLM 的时候,如果想让模型的生成结果更加多样化,可以通过调高 top_p 或者 temperature 来实现,反之,如果调低这两个参数,则生成的结果会更加倾向同质化,总之,两种方式的应用场景不同。这篇文章我们通过示例从原理上来解释为何这两个参数能够控制 LLM 生成结果的多样性。
首先需要知道,LLM 的输出结果只是下一个 token 的概率分布,具体生成框架(比如 transformers 的 generate 函数)负责生成过程。如果采用贪心策略,每次都选择概率最大的 token,那么就不存在所谓的调整空间,也就是说当设置 do_sample=False 时,top_p 和 temperature 参数是不起作用的。而当设置 do_sample=True 时,生成框架才会根据概率对 token 进行采样,这时 top_p 和 temperature 参数才会发挥作用。
为了更好的说明,我们使用 gpt2 模型产生一个概率分布
tokenizer = AutoTokenizer.from_pretrained("gpt2")
model = AutoModelForCausalLM.from_pretrained("gpt2").cuda()
model.eval()
text = "hello, this is my favorite"
input_ids = tokenizer.encode(text, return_tensors="pt").cuda()
attention_mask = torch.ones_like(input_ids).cuda()
with torch.no_grad():
outputs = model(input_ids, attention_mask = attention_mask)
logits=outputs["logits"][0, -1, :]
这里的 logits 就是下一个token的未归一化概率分布,如果我们设置了 temperature 参数,那么生成框架会对这个 logits 进行调整,具体来说就是对其除以 temperature。然后再通过 softmax 将 logits 变换为归一化的概率分布,并在这个分布的基础上进行采样。下面我们使用 temperature=0.9 以及 temperature=0.1 为例,看看这两种情况对归一化概率的影响
temperature = 0.9
logits = logits / temperature
probs = F.softmax(logits, dim=-1).cpu().numpy()
## sort
sorted_idx = np.argsort(probs)[::-1]
sorted_probs = probs[sorted_idx][:20]
## plot
plt.plot(sorted_probs)
这里我们绘制出了概率值最大的前20个数据
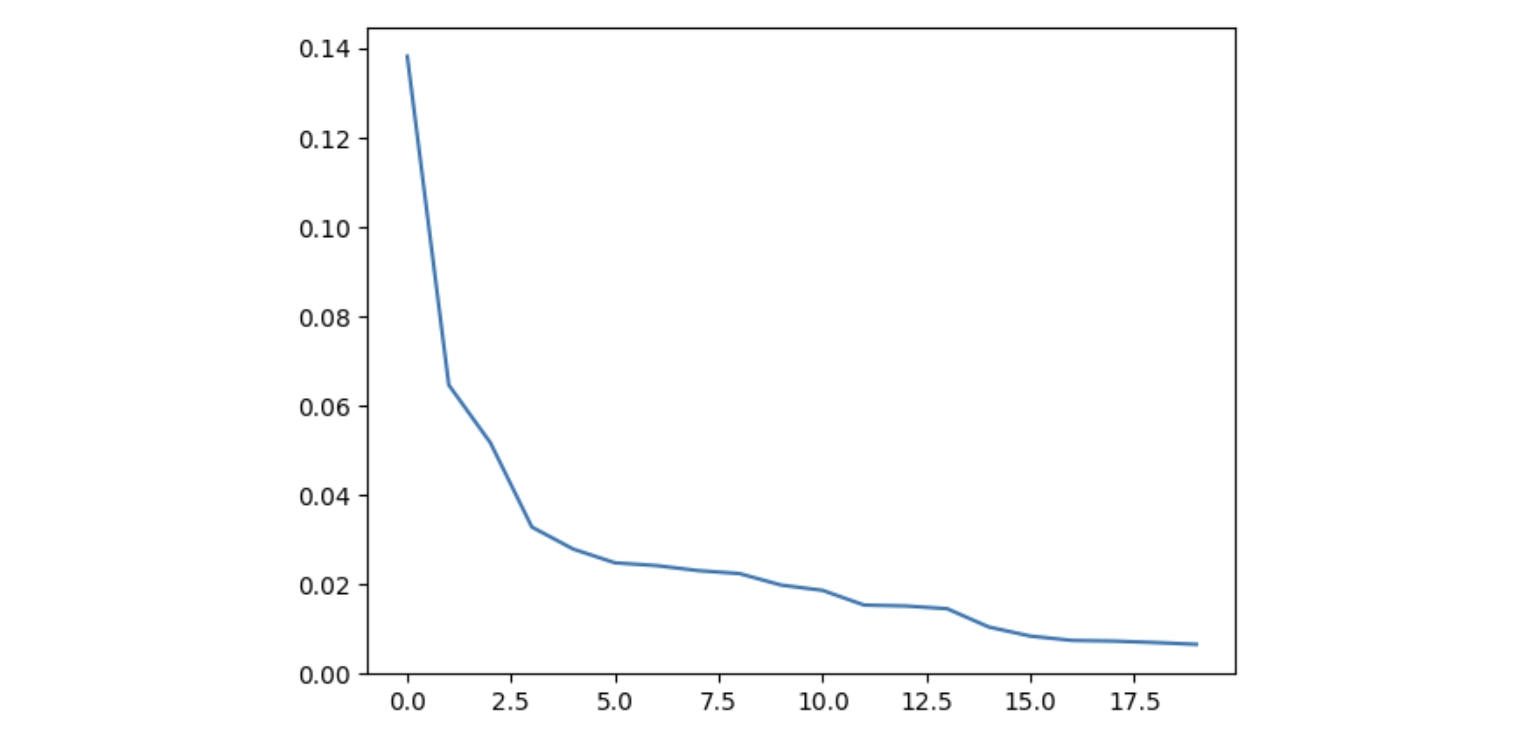
接下来我们将 temperature 设置为 0.1,其他不变,再次绘制概率值最大的前20个数据
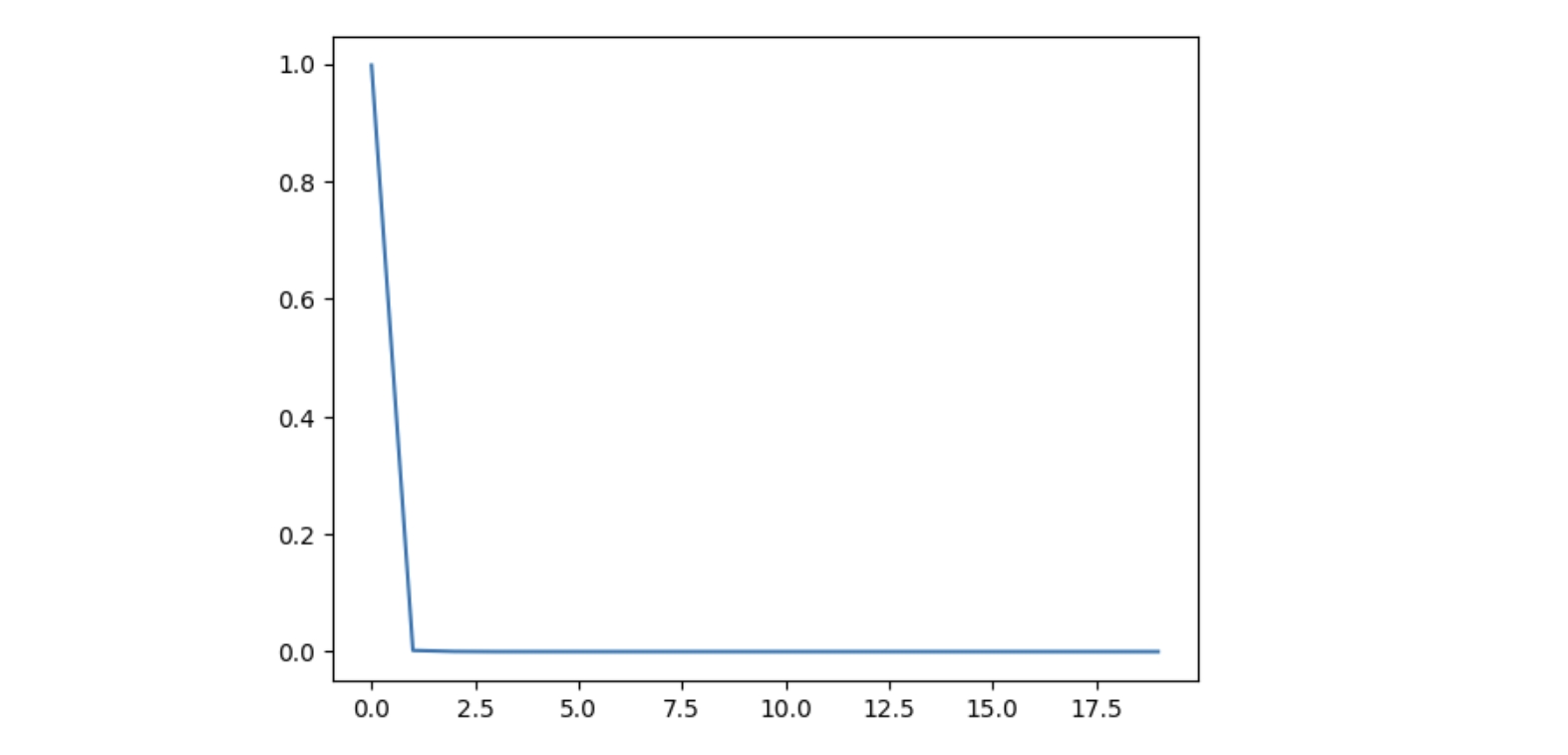
可以看到相对于 temperature=1 的情况,这时概率的分布更集中了,生成框架会更倾向于选择概率最大的 token,于是生成结果的多样性也就变小了。
通过这个例子我们也可以理解为什么这个参数被命名为 temperature。我们知道在物理世界中,温度越高的环境,熵越大,对应到概率世界中,熵越大,概率的不确定性越大,也就是概率分布越不集中,这就是第一种情况,而当温度越低,熵越小,概率分布就越集中,这就是第二种情况。所以 temperature 本质是在控制概率分布的熵,从而影响生成结果的多样性。
接下来我们再考虑 top_p 的具体作用,top_p 实际上是个阈值参数,它对 logits 的修改有点绕,我们一步一步说明(具体代码见 transformers 的 src/transformers/generation/logits_process.py 文件 TopPLogitsWarper 类)
- 首先对
logits按从小到大的顺序排序; - 使用 softmax 计算归一化概率,然后计算累计概率,如下图所示
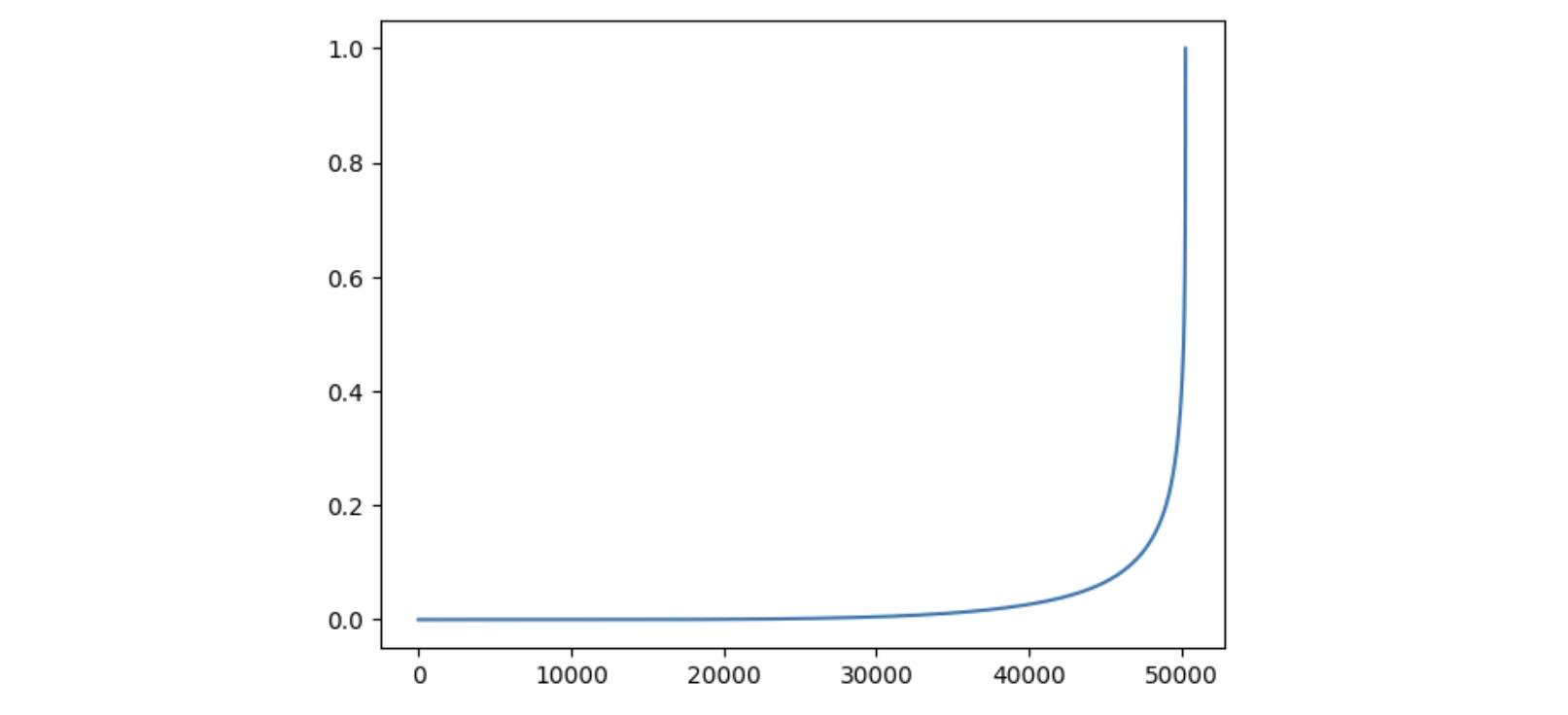
- 过滤掉小于
1-top_p的值,并将其所在的 token 的概率设为负无穷; - 重新计算归一化概率,然后进行采样。
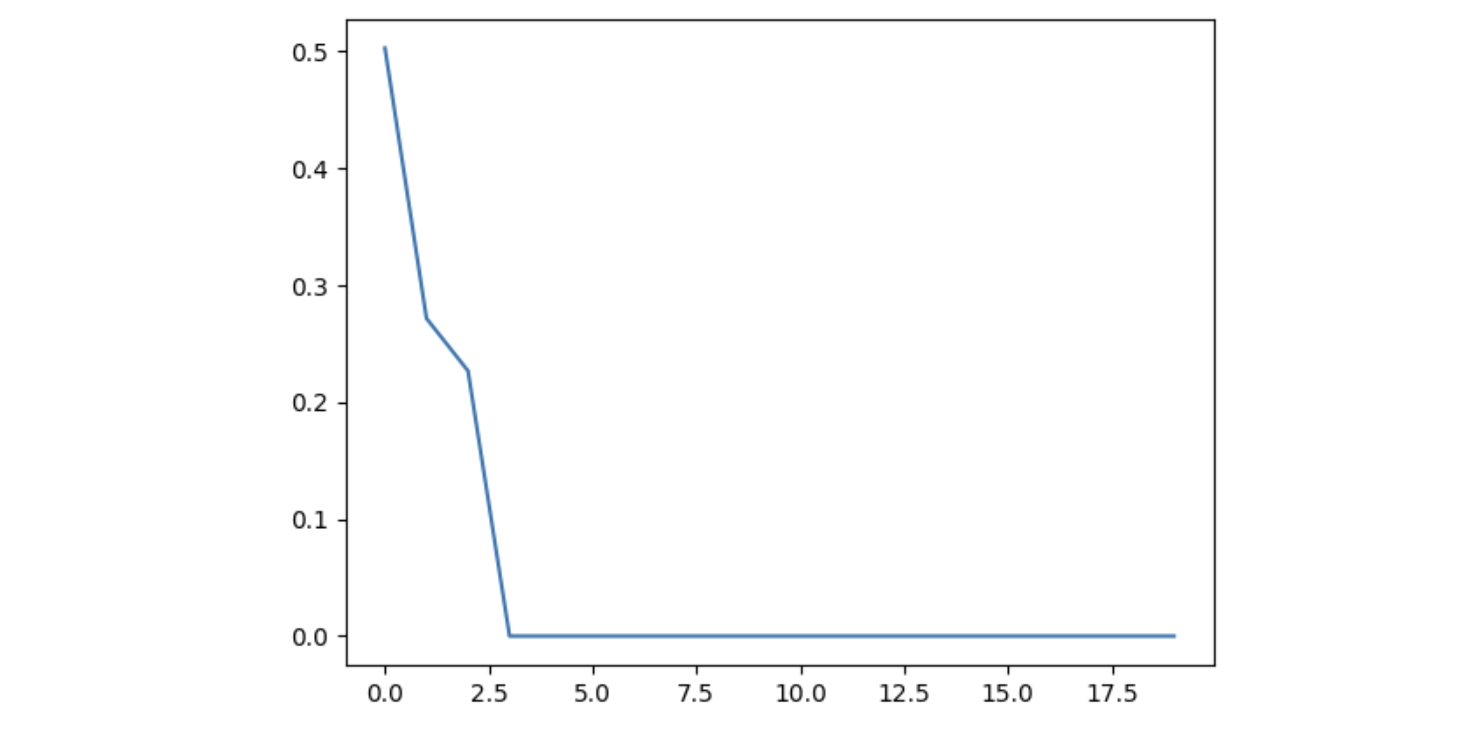
可以发现,top_p 越小,则过滤掉的小概率 token 越多,采样时的可选项目就越少,生成结果的多样性也就越小。我们使用一个例子来说明,分别设置 top_p = 0.9 和 top_p = 0.1。
top_p = 0.9
sorted_logits, sorted_indices = torch.sort(logits, descending=False)
cumulative_probs = sorted_logits.softmax(dim=-1).cumsum(dim=-1)
# Remove tokens with cumulative top_p above the threshold (token with 0 are kept)
sorted_indices_to_remove = cumulative_probs <= (1 - top_p)
# scatter sorted tensors to original indexing
indices_to_remove = sorted_indices_to_remove.scatter(0, sorted_indices, sorted_indices_to_remove)
scores_processed = logits.masked_fill(indices_to_remove, -float('inf'))
probs = F.softmax(scores_processed, dim=-1)
## sort
sorted_probs, sorted_indices = torch.sort(probs, descending=True)
## top 20
plt.plot(sorted_probs[:20].cpu().numpy())
这里我们借用了 transfromers 的代码,绘制出概率值最大的前20个数据
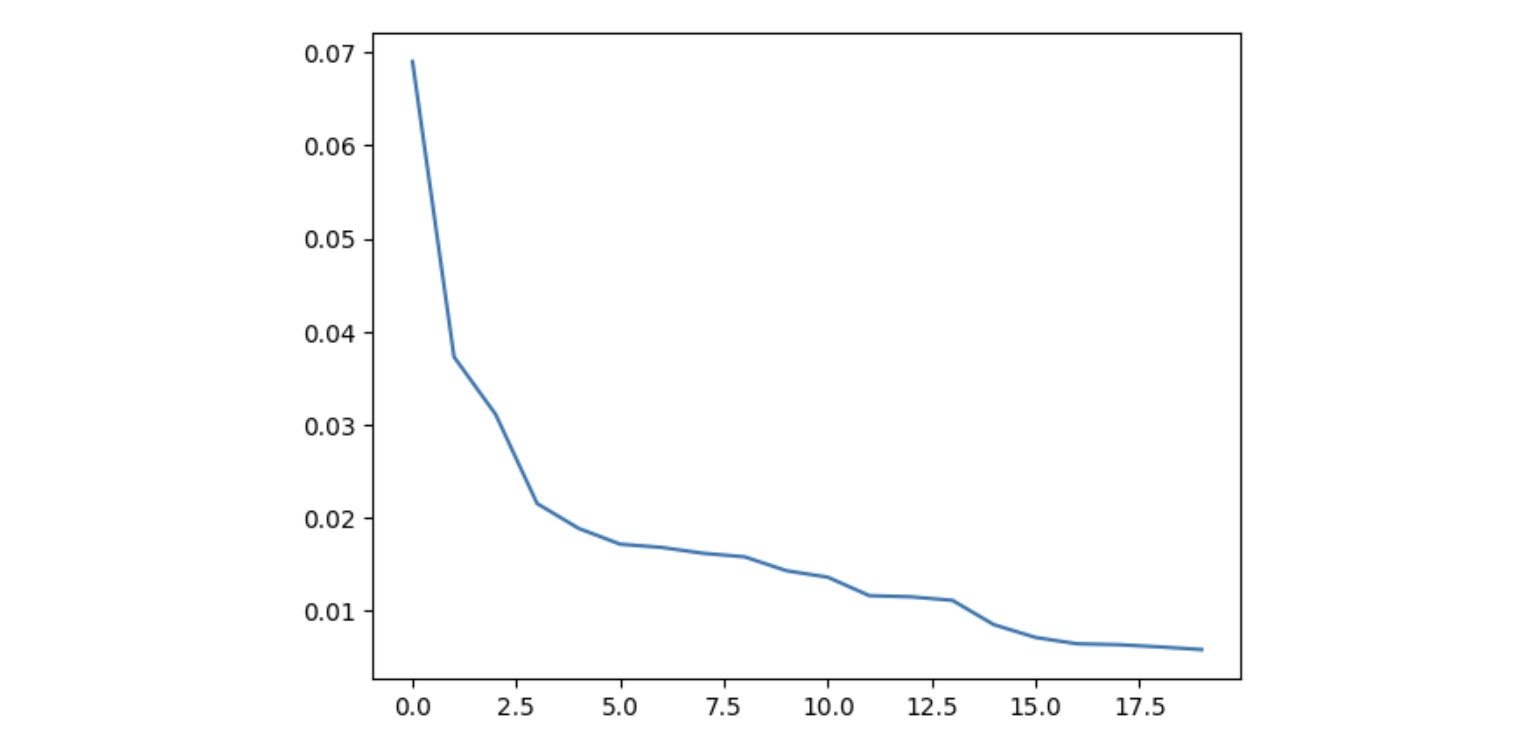
而当 top_p=0.1 时,情况类似于 temperature=0.1,可以看到概率分布的集中度也变大了。
通过上面的分析与实例,我们可以看到 top_p 和 temperature 这两个参数是如何影响 LLM 生成结果的多样性的。temperature 控制了概率分布的熵,从而影响生成结果的多样性,而 top_p 则是通过过滤掉小概率的 token,减少采样的可选项,从而影响生成结果的多样性。
最后,如果我们用概率分布的熵来量化生成结果的多样性,那么 temperature 和 top_p 在同样数值的情况下,哪个参数的影响会更大?在不同模型之间会不会有一些规律?感兴趣的同学可以实验验证一下。