TensorRT 使用指南(4):SadTalker 模型加速方案
介绍
SadTalker 是一个 face reenactment 项目,来自论文 SadTalker: Learning Realistic 3D Motion Coefficients for Stylized Audio-Driven Single Image Talking Face Animation。本文不研究具体的算法原理,而是专注于使用 TensorRT 对原模型推理进行加速。
正确部署后,直接运行示例程序 python inference.py,出现下图所示的任务日志

可以看到,在这几个推理阶段中,最后的 Face Renderer 耗时最严重,因此我们这里主要来对这个模型进行优化。
当前测试的系统环境为:
System: Centos 7
GPU: V100 16G
Python Version: 3.8.8 / 3.10.2
CUDA Version: 11.7 / 12.0
Torch Version: 2.0.0+cu117
TensorRT Version: 8.6.1
ONNX Version: 1.15.0
在其他环境下可能会出现不一样的行为。
修改 forward 方法的参数参数
对代码进行分析后,可以找到 src/facerender/modules/generator.py 中的 OcclusionAwareSPADEGenerator,这就是 Face Renderer 阶段的推理模型,它的 forward 方法为
def forward(self, source_image, kp_driving, kp_source):
其中,kp_driving 和 kp_source 都是 dict 类型,包含的 key 可能有 value 和 jacobian,为了方便使用 torch.onnx.export,这里我们复制一份 generator_v2.py,把以上 forward 的参数拆出来,全部变成 Tensor 类型,也就是
def forward(self, source_image, kp_driving, kp_source, kp_driving_jacobian = None, kp_source_jacobian = None)
其中 kp_driving 是原 kp_driving 的 value 部分,kp_driving_jacobian 是 jacobian 部分,kp_source 也类似。然后对后续代码进行相应修改即可。
导出 generator 的模型权重和样本输入
我们首先在原文件夹下创建目录 tensorrt/generator 作为工作空间存放相关代码和数据。参考 inference.py 的代码加载模型
sadtalker_paths = init_path(args.checkpoint_dir, os.path.join(current_root_path, 'src/config'), args.size, args.old_version, args.preprocess)
animate_from_coeff = AnimateFromCoeff(sadtalker_paths, device)
然后,通过 anime_from_coeff.generator 获得 OcclusionAwareSPADEGenerator 的实例,然后调用 state_dict 方法获得模型权重,最后保存为 pth 文件。
torch.save(animate_from_coeff.generator.state_dict(), "tensorrt/generator/model.pth")
对于样本输入,为了方便起见,我们再次运行 inference.py,并在原 OcclusionAwareSPADEGenerator 的 forward 方法中存储输入和输出
torch.save(source_image, './tensorrt/generator/source_image.pt')
torch.save(kp_driving, './tensorrt/generator/kp_driving.pt')
torch.save(kp_source, './tensorrt/generator/kp_source.pt')
为了后续验证模型的正确性,还可以用同样的方法保存输出张量。
PyTorch 模型转 ONNX
在 tensorrt/generator 下面创建 export_onnx.py 文件,假设我们已经加载了模型和数据,使用如下代码导出 ONNX 模型
symbolic_names = {0: "batch_size"}
torch.onnx.export(model=model,
args = (source_image, kp_driving, kp_source, kp_driving_jacobian, kp_source_jacobian),
f = "./model.onnx",
opset_version=16,
do_constant_folding=True,
input_names=["source_image", "kp_driving", "kp_source", "kp_driving_jacobian", "kp_source_jacobian"],
output_names=["prediction"],
dynamic_axes={
"source_image": symbolic_names,
"kp_driving": symbolic_names,
"kp_source": symbolic_names
}
)
其中 symbolic_names 表明 batch_size 为动态维度。注意这里的 opset_version 为 16,因为在这个版本中才支持 torch.nn.functional 的 grid_sample 算子。但即便这样,直接运行仍然会报错:
torch.onnx.errors.OnnxExporterError: Unsupported: ONNX export of operator GridSample with 5D volumetric input. Please feel free to request support or submit a pull request on PyTorch GitHub: https://github.com/pytorch/pytorch/issues
这是因为 ONNX 暂时还不支持三维的 grid_sample 操作,这个算子在 src/facerender/modules/dense_motion.py 的 create_deformed_feature 方法中有用到。PyTorch 目前对这种情况做了限制[1],但实际上直接把 pytorch 安装目录下的 torch/onnx/symbolic_opset16.py 中的检查代码直接注释掉就可以了。
if symbolic_helper._get_tensor_rank(input) == 5:
return symbolic_helper._onnx_unsupported("GridSample with 5D volumetric input")
因为 ONNX 本身是支持二维 grid_sample 操作的,而我们并不会使用 ONNX Runtime 运行模型,所以直接导出没有问题,导出后可以使用 Netron 找到 GridSample 节点
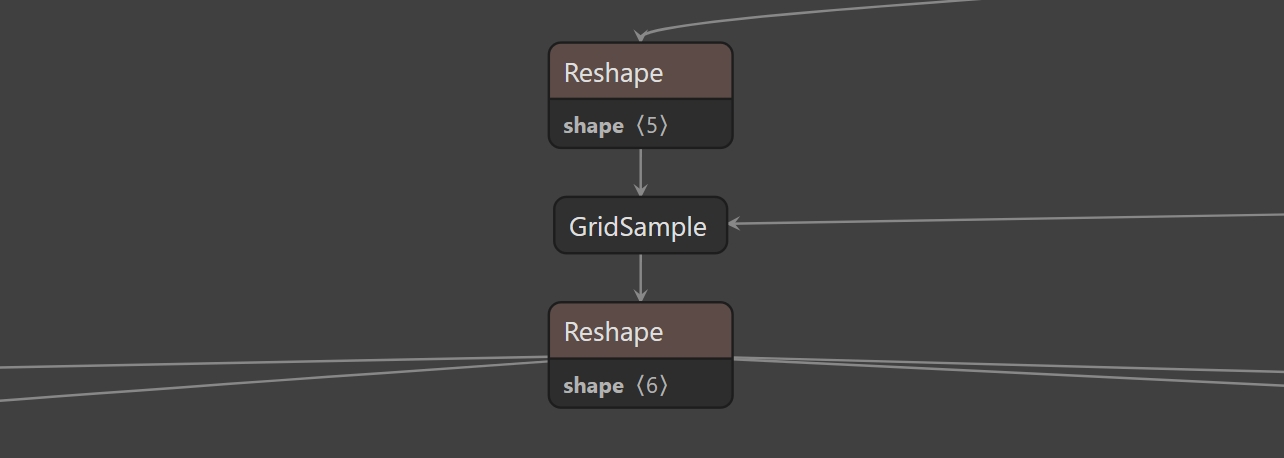
当然我们这里捡了一点便宜,如果是 ONNX 完全不支持的算子,就要用点其他手段了。
解决掉 grid_sample 算子的问题之后,可能会遇到另外一个报错:
torch.onnx.errors.SymbolicValueError: Unsupported: ONNX export of instance_norm for unknown channel size.
这涉及到 instance_norm 算子,位于 src/facerender/modules/util.py 下的 SPADE 模块
self.param_free_norm = nn.InstanceNorm2d(norm_nc, affine=False)
貌似这个实现是有点问题,解决方案是我们自己实现这个 InstanceNorm2d 模块[2]。
class InstanceNorm2dAlt(nn.InstanceNorm2d):
def forward(self, inp: torch.Tensor) -> torch.Tensor:
self._check_input_dim(inp)
desc = 1 / (inp.var(axis=[2, 3], keepdim=True, unbiased=False) + self.eps) ** 0.5
retval = (inp - inp.mean(axis=[2, 3], keepdim=True)) * desc
return retval
解决了这两个问题之后,后面应该能正常导出了。
使用 onnx_graphsurgeon 对 ONNX 模型进行修改
前面我们提到 ONNX 不支持三维 grid_sample 操作,其实 TensorRT 也不支持。。所以直接往 TenosrRT 转的话又会报错,所以我们的方案是修改这个节点的名称,避免 TensorRT 使用自己的 grid_sample 算子,,然后使用插件来实现这个算子。Nvidia 提供了一个比较方便的工具 onnx_graphsurgeon 可以帮助我们来修改 ONNX 计算图,由于这个包是托管在 Nvidia 自己的服务器上,所以使用 pip 安装需要额外指定 url
python3 -m pip install onnx_graphsurgeon --index-url https://pypi.ngc.nvidia.com
当然很可能因为网络问题下载不下来,备选方案是用下面这个地址
https://developer.download.nvidia.com/compute/redist/onnx-graphsurgeon/
安装完成之后,只需要修改 GridSample 节点的名称
import onnx
import onnx_graphsurgeon as gs
model = onnx.load("model.onnx")
graph = gs.import_onnx(model)
for node in graph.nodes:
if "GridSample" in node.name:
node.attrs = {"name": "GridSample3D", "version": 1, "namespace": ""}
node.op = "GridSample3D"
onnx.save(gs.export_onnx(graph), "./model_gs.onnx")
这样 TensorRT 就不会尝试用自己的 GridSample 实现去检查这个节点了,而是尝试找到 GridSample3D 这个插件。
使用自定义插件实现 GridSample3D 算子
将 ONNX 模型转换到 TensorRT Engine
编译出插件的 .so 动态链接库之后,可以在 python 代码中加载
trt.init_libnvinfer_plugins(logger, "")
handle=ctypes.CDLL("../plugin/build/libgrid_sample_3d_plugin.so", mode = ctypes.RTLD_GLOBAL)
if not handle:
print("load grid_sample_3d plugin error")
其中 plugin 为插件的目录,位于 tensorrt 下面。剩下的就是正常的转换流程,可以参考第一节的内容。
编写基于 TensorRT 的 generator
为了充分利用原有代码框架,我们在 src/facerender/modules 目录下创建 generator_trt.py 文件,并实现自己的 OcclusionAwareSPADEGenerator 类
class OcclusionAwareSPADEGenerator:
def __init__(self, engine_path: str, plugin_path: str):
logger = trt.Logger(trt.Logger.VERBOSE)
success = ctypes.CDLL(plugin_path, mode = ctypes.RTLD_GLOBAL)
if not success:
print("load grid_sample_3d plugin error")
raise Exception()
trt.init_libnvinfer_plugins(logger, "")
self.engine, self.context = load_engine(engine_path, logger)
def __call__(self, source_image, kp_driving, kp_source):
kp_driving_jacobian = kp_driving["jacobian"] if "jacobian" in kp_driving else None
kp_source_jacobian = kp_source["jacobian"] if "jacobian" in kp_source else None
kp_driving = kp_driving["value"]
kp_source = kp_source["value"]
inputs = {
"source_image": source_image,
"kp_driving": kp_driving,
"kp_source": kp_source,
"kp_driving_jacobian": kp_driving_jacobian,
"kp_source_jacobian": kp_source_jacobian
}
"""
{
"mask": mask,
"occlusion_map": occlusion_map,
"prediction": prediction
}
"""
output = inference(self.engine, self.context, inputs)
return output
其中 load_engine 和 inference 方法可以参考第一节。
然后再复制一份 src/facerender/animate.py 文件为 animate_trt.py,并将其中的 generator 修改为
from src.facerender.modules.generator_trt import OcclusionAwareSPADEGenerator
generator = OcclusionAwareSPADEGenerator("./tensorrt/generator/model.engine", "./tensorrt/plugin/build/libgrid_sample_3d_plugin.so")
并删除原来的 generator 相关代码,比如加载权重等等,然后在 inference.py 文件中替换导入
from src.facerender.animate_trt import AnimateFromCoeff
最后运行 python inference.py,可以看到在 fp16 精度下有大致 2.5 倍的速度提升

如果按 24 帧的视频来看,已经达到了实时生成的目的。
总结
本文介绍了如何使用 TensorRT 对 SadTalker 模型进行加速,比较新的知识点在于 grid_sample 算子的实现,以及如何修改 ONNX 模型,让 TensorRT 使用自定义插件来实现这个算子。
目前来看,以上介绍的方案在 float32 精度下加速效果不是很明显,可能只有 1.x 倍的提升,而在 fp16 精度下虽然有 2.5 倍的提升,但是生成的视频质量会有所下降,是一个待解决的问题。
参考
[1] https://github.com/pytorch/pytorch/pull/92212
[2] https://stackoverflow.com/questions/72187686/exception-when-converting-unet-from-pytorch-to-onnx