CUDA 编程入门(6):共享内存
算术强度的计算问题
前面我们在介绍算术强度的时候,非常理想化的把内存读取总量等价成了参与运算的数据总量。但实际上,由于寄存器数量限制,没法完全容纳全部的数据量,每个数据往往需要读很多次,因此实际的算术强度只可能比理论值更低。
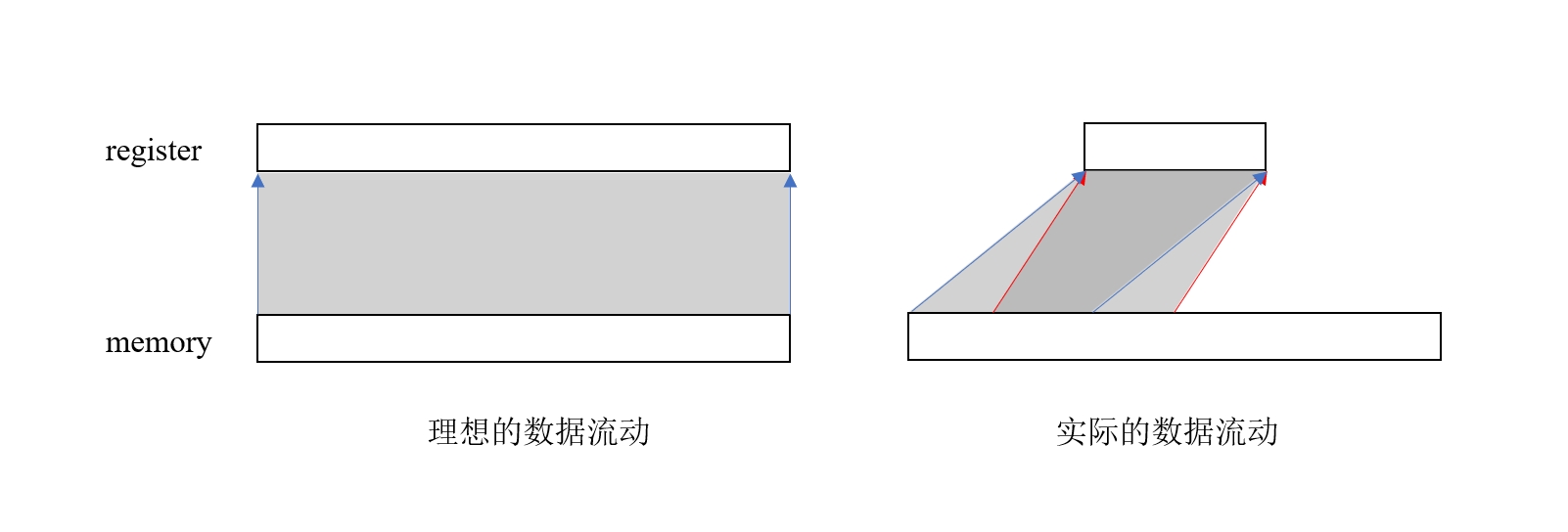 图 1. 数据流动示意图
图 1. 数据流动示意图
上图右边展示了实际的数据流动过程,每次加载只能读取一部分数据到寄存器,这部分数据算完之后,再读下一部分,由于算法的原因,两次计算之间有可能需要用到一些相同的数据,因此存在重复加载的现象。
共享内存的作用
通过上一节的分析我们可以看到,寄存器容量的限制会直接导致算法的实际算术强度达不到理论值,会对程序的性能造成不利影响。在没法无限制增加寄存器数量的情况下,一种折中的方案就是用一块速度比普通内存块,容量比寄存器大的特殊区域来做中间存储,也就是共享内存。很明显这就是一种缓存思想,事实上,共享内存也确实位于 L1 缓存上,但它们的不同点在于,共享内存是可编程的,也就是说我们可以显式的将数据存到共享内存再显式的读取,而缓存则不具备这样的功能。
有了共享内存之后,我们就可以把需要重复利用的数据先加载到共享内存中,虽然从共享内存到寄存器仍然存在重复加载的问题,但由于它们之间的速度极快,所以对性能的影响相对于普通内存来说就小很多了。
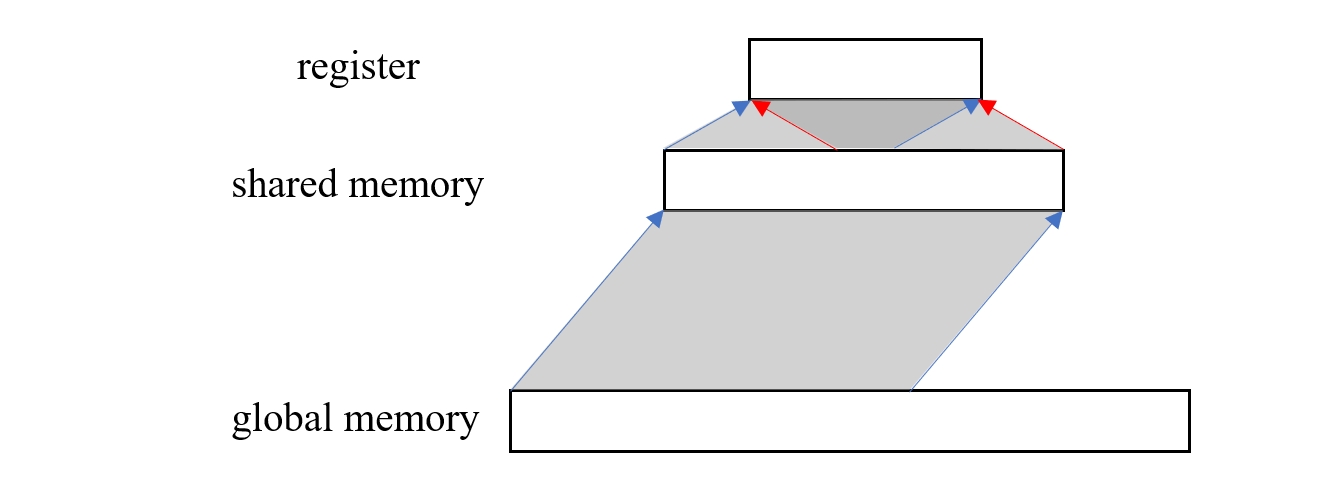 图 2. 加入共享内存之后的数据流动示意图
图 2. 加入共享内存之后的数据流动示意图
使用共享内存对矩阵乘法进行简单优化[1]
矩阵乘法可以说是一种最为常见的运算,尤其是在神经网络中,无论是全连接层计算,还是 CNN 的卷积运算,再或是 Transformer 中的注意力计算,本质上都是在运用矩阵乘法。因此,对矩阵乘法的优化非常重要,其优化手段也多种多样,这一节我们主要还是展示共享内存对它的优化效果。
并行矩阵乘法的 baseline 实现
我们先来看一下在 GPU 上如何实现一个最基础的矩阵乘法 kernel,设矩阵 A, B, C 的尺寸分别为 M x K, K x N, M x N,计算 C = A x B。根据 CUDA 的分层模型,我们将矩阵 C 分成两个 block 和 thread 两个级别的计算层次,其中每个 block 负责计算 C 中的一个区块,我们用 Csub 来表示,thread 负责计算 Csub 中的一个元素。由于当前 GPU 架构下每个 block 中的 thread 数量最多为 1024 个,因此我们将 block 的尺寸设置为 32 x 32。根据矩阵乘法的计算规则,每个 block 负责读取矩阵 A 中的一行条带,以及矩阵 B 中的一列条带,条带宽度等于 32。
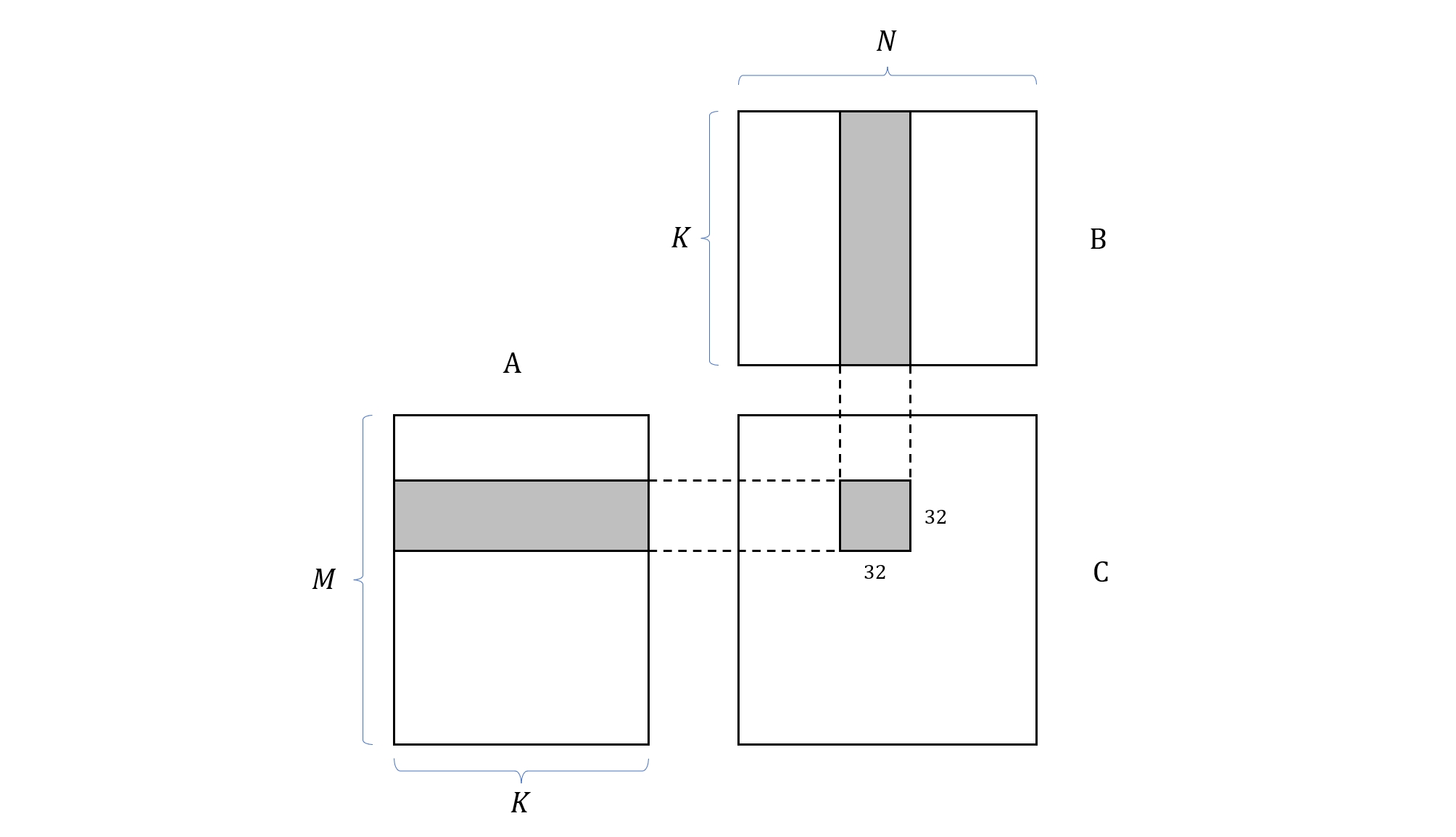 图 3. 矩阵乘法的 block 划分示意图
图 3. 矩阵乘法的 block 划分示意图
在这样的任务分割条件下,grid 的尺寸就可以通过矩阵 C 的尺寸来确定了,在行方向上为 (M + 32 - 1) / 32,在列方向上 (N + 32 - 1) / 32。
而在每个 block 内部,每个 thread 负责读取 A 条带的一行元素,以及 B 条带的一列元素,并进行点积运算,最后将结果写入到 C 中的对应位置。为了计算当前 thread 在 C 中的位置,需要用到当前 thread 在 block 中的位置 (threadIdx.x, threadIdx.y),以及当前 block 在 grid 中的位置 (blockIdx.x, blockIdx.y),计算公式为
int row = blockIdx.y * 32 + threadIdx.y;
int col = blockIdx.x * 32 + threadIdx.x;
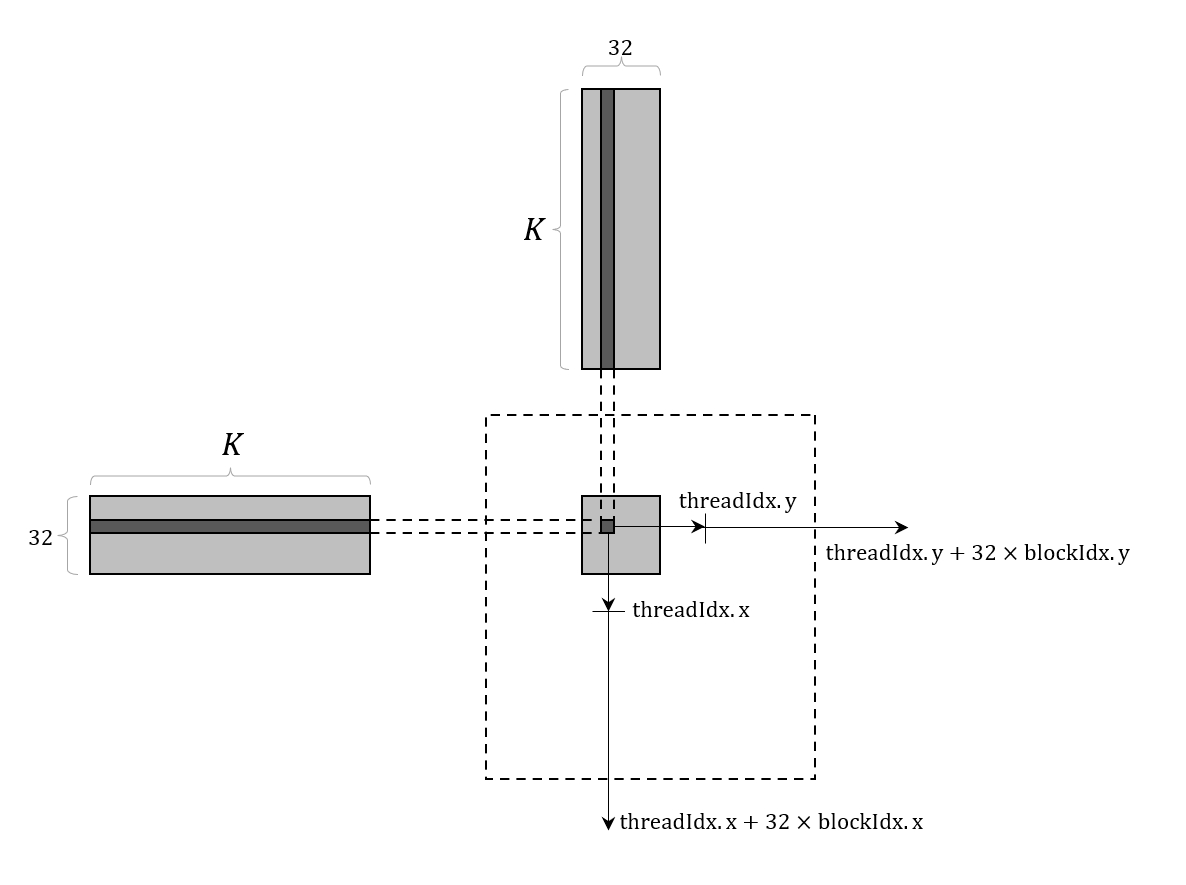 图 4. 矩阵乘法的 thread 划分示意图
图 4. 矩阵乘法的 thread 划分示意图
经过上面的描述,我们就可以写出一个最基础的矩阵乘法 kernel 了
template <typename T>
__global__ void matmul_kernel_0(T* A, T* B, T* C, int M, int K, int N) {
int row = blockIdx.y * 32 + threadIdx.y;
int col = blockIdx.x * 32 + threadIdx.x;
if(row >= M || col >= N) return;
T sum = 0;
for(int k = 0; k < K; k++) {
sum += A[row * K + k] * B[k * N + col];
}
C[row * N + col] = sum;
}
下面我们分析一下内存访问情况,由于每个 thread 需要读取矩阵 A 的一行元素,且矩阵 C 的列数等于 N,那么计算 C 的完整一行需要读取 N 次 A 矩阵的对应行,于是计算完 C 需要读取 N 次矩阵 A,同理,还需要读取 M 次矩阵 B,显然,这种情况对算术强度的影响是相当大的。
使用共享内存优化矩阵乘法
为了不那么多次重复的从 global memory 中读取数据,可以考虑利用比 global memory 快得多的共享内存来做中间存储。根据前面的讨论,最理想的情况当然是让每个 block 将 A 的一个行条带和 B 的一个列条带全部加载到共享内存中,然后再按照相同的方式计算 Csub。但需要注意的是,共享内存容量虽然比寄存器大,但也不是无限的,完整加载 A 的一行条带需要存储 32 x K 个元素,当 K 比较大的时候,很可能就存不下了,所以一种比较保险的方式是分多次加载(具体来说,是(K + 32 - 1) / 32次),并将结果累加到 Csub 即可。具体过程可以参考下图
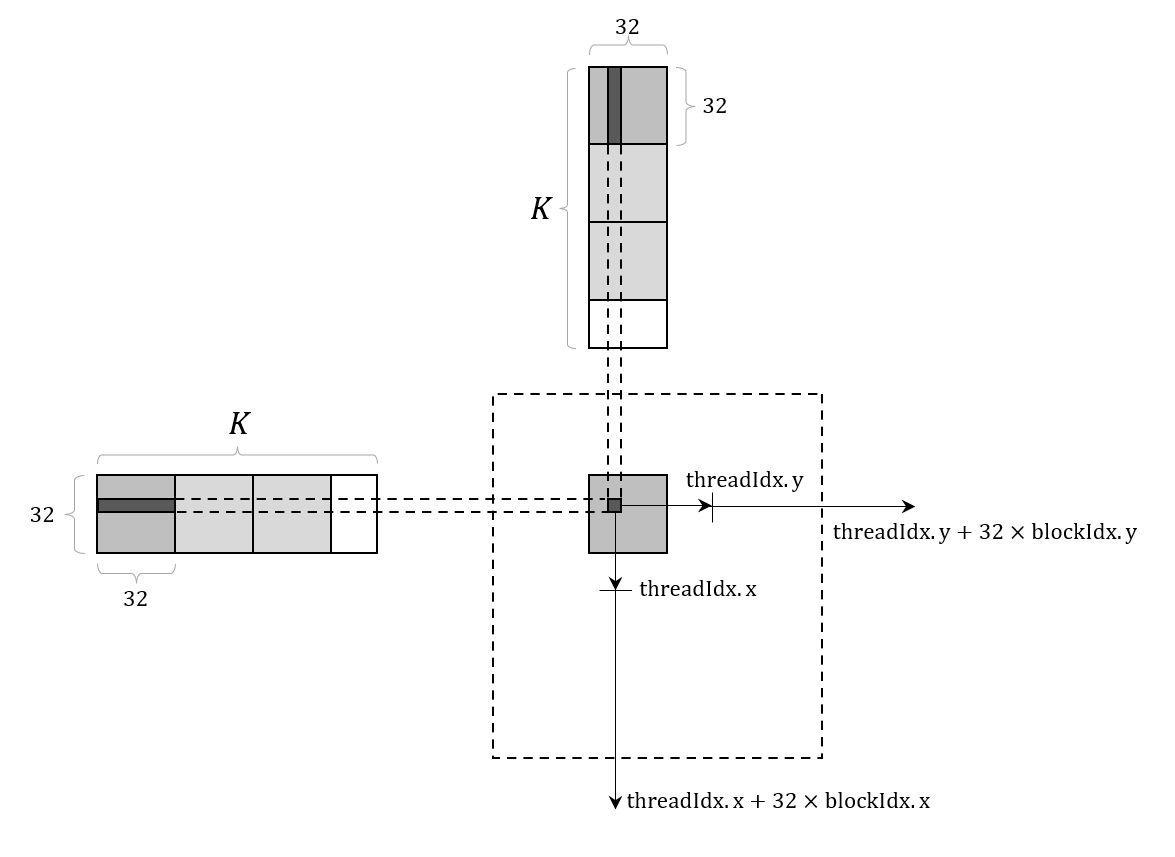 图 5. 使用共享内存优化矩阵乘法的 thread 划分示意图
图 5. 使用共享内存优化矩阵乘法的 thread 划分示意图
在上面描述的方法中,计算 Csub 仅需要从 global memory 中读取一次 A 的行条带和 B 的列条带,由于 Csub 的尺寸为 32 x 32,因此总共需要从 global memory 中读取 M / 32 + N / 32 次,相比于 baseline 实现,这种方式的内存访问次数大大减少了,因此算术强度也会相应提高。
下面是对应的 kernel 实现
template <typename T>
__global__ void matmul_kernel_1(T* A, T* B, T* C, int M, int K, int N) {
int row = blockIdx.y * 32 + threadIdx.y;
int col = blockIdx.x * 32 + threadIdx.x;
if(row >= M || col >= N) return;
__shared__ T As[32 * 32];
__shared__ T Bs[32 * 32];
int numBlocks = (K + 32 - 1) / 32;
T sum = 0;
for (int i = 0; i < numBlocks; i++) {
int x_A = i * 32 + threadIdx.x;
int y_A = blockIdx.y * 32 + threadIdx.y;
As[threadIdx.y * 32 + threadIdx.x] = A[y_A * K + x_A];
int x_B = blockIdx.x * 32 + threadIdx.x;
int y_B = i * 32 + threadIdx.y;
Bs[threadIdx.y * 32 + threadIdx.x] = B[y_B * N + x_B];
__syncthreads();
for(int k = 0; k < 32; k++) {
sum += As[threadIdx.y * 32 + k] * Bs[k * 32 + threadIdx.x];
}
__syncthreads();
}
C[row * N + col] = sum;
}
代码中的 As, Bs 就是我们申请的共享内存区域,它们都由 __shared__ 修饰。比较复杂的地方是 for 循环中对每个 thread 需要加载的 A, B 元素坐标的计算,以 A 矩阵为例,当前 block 坐标为 (blockIdx.x, blockIdx.y),当前 thread 坐标为 (threadIdx.x, threadIdx.y),那么第 i 次加载时,对应元素坐标就为
int x_A = i * 32 + threadIdx.x;
int y_A = blockIdx.y * 32 + threadIdx.y;
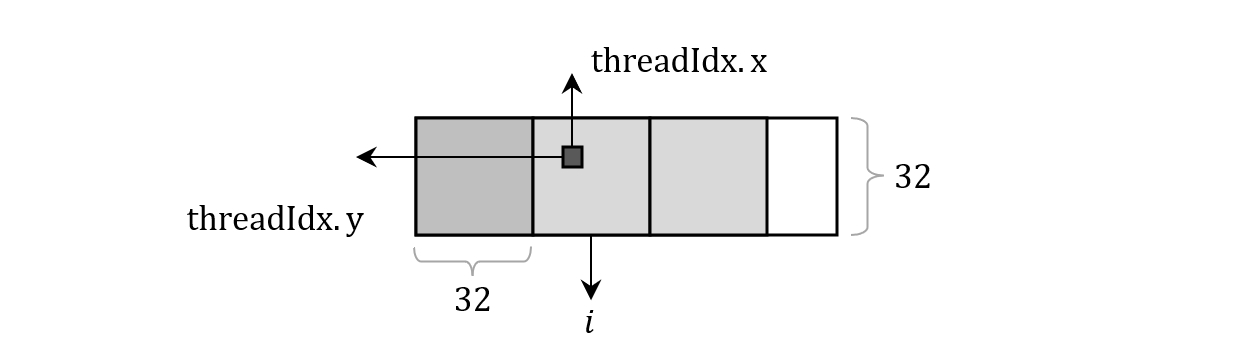 图 6. A 矩阵元素坐标计算示意图
图 6. A 矩阵元素坐标计算示意图
以上就是通过共享内存优化矩阵乘法的具体思路,加速效果不同的硬件可能不太一样,我就懒得贴了,完整代码可以参考这里,感兴趣可以看看。
参考
[1] 这一节我们主要参考 CUDA 官方文档中对矩阵乘法的示例。