CUDA 编程入门(5):程序计时与性能指标
程序计时[1]
既然我们专注于高性能计算,那么程序的运行时间就是一个非常值得关注的指标,在 CUDA 中,提供了很有用的 API 来帮助我们对程序在 Device 端的运行时间进行统计。下面的代码展示了如何来使用这些工具:
void vectorAdd(const float *a,
const float *b,
const int n,
float* c) {
float *d_a, *d_b, *d_c;
cudaMalloc((void**)&d_a, n * sizeof(float));
cudaMalloc((void**)&d_b, n * sizeof(float));
cudaMalloc((void**)&d_c, n * sizeof(float));
cudaMemcpy(d_a, a, n * sizeof(float), cudaMemcpyHostToDevice);
cudaMemcpy(d_b, b, n * sizeof(float), cudaMemcpyHostToDevice);
int block_size = BLOCK_SIZE;
int grid_size = (n + block_size - 1) / block_size;
// 声明开始和结束事件
cudaEvent_t start, stop;
cudaEventCreate(&start);
cudaEventCreate(&stop);
// 记录开始事件
cudaEventRecord(start);
vector_add_kernel<<<grid_size, block_size>>>(d_a, d_b, n, d_c);
// 记录结束事件
cudaEventRecord(stop);
// 等待kernel执行完成
cudaEventSynchronize(stop);
// 计算事件时间差
float time = 0;
cudaEventElapsedTime(&time, start, stop);
printf("time: %f ms\n", time);
cudaMemcpy(c, d_c, n * sizeof(float), cudaMemcpyDeviceToHost);
cudaFree(d_a);
cudaFree(d_b);
cudaFree(d_c);
}
CUDA API 记录时间的逻辑很简单,首先是声明了两个事件分别代表开始和结束,然后在 kernel 执行前后分别记录这两个事件,最后通过 cudaEventElapsedTime 计算时间差。值得注意的是 cudaEventSynchronize() 方法,它的作用是阻塞 Host 线程,直到 Device 端的 kernel 执行完成,因为 kernel 函数执行相对于 Host 线程来说是异步的。
内存吞吐量(Memory Throughput)
获得程序运行时间之后,我们就可以测量内存吞吐量来评估程序的内存性能,然后通过比较硬件的内存带宽来评估程序的内存利用效率。内存吞吐量的计算公式为
\[T = \frac{N}{t}\]其中 $N$ 表示程序运行过程中从内存中读写的数据量,通常以字节为单位,$t$ 表示程序运行时间,单位为秒。所以吞吐量的单位就是 byte/s,或者更常用的 GB/s。比如上面的程序中,设 n = 1<<25,每个浮点数占 4 个字节,每次加法运算涉及 3 次内存操作(2次读取+1次写入),于是 N = n x 4 x 3 = 0.375GB,假如 kernel 的执行时间为 2ms,那么程序的内存吞吐量就是 0.375GB / 2ms * 1000ms/s = 187.5GB/s。
运算吞吐量(Compute Throughput)
除了内存吞吐量外,还有一个重要的性能指标是运算吞吐量,它的含义是单位时间内,处理器能够完成的浮点运算次数,基本单位是 FLOPS,对于更高量级,通常还可以用 GFLOPS 和 TFLOPS。运算吞吐量对应的硬件指标是计算性能,通过比较程序的运算吞吐量和硬件的计算性能,我们可以评估程序的计算利用效率。
算术强度(Arithmetic Intensity)
算术强度是算法自身的一种性能特性,其定义是完成算法需要的浮点运算量与内存读写量的比值,常用的单位是 FLOP/byte。算术强度越高,说明算法的计算密集度越高,反之则说明算法的内存密集度越高。以 n x n x n 的矩阵乘法 C = A x B 为例,矩阵 C 中的每个元素对应 A 的一行点积 B 的一列,也就是 n 次乘法和 n - 1 次加法运算,那么总的浮点运算量就是 n x n x (n + n - 1)。而从内存读写来看,最好的情况下,A 和 B 矩阵需要各读取一次,C 矩阵需要写入一次,因此总的内存读写量就是 3 x n x n x 4byte。于是,矩阵乘法的算术强度就是
Roofline 模型[2][3]
Roofline 模型是一种用来评估程序在特定硬件设备上的运行性能的可视化模型。对于特定硬件来说,计算密集型程序主要是受到计算能力的限制,被称为 compute bound,内存密集型程序主要受内存带宽的限制,被称为 memory bound。区分一个程序是 compute bound 或者 memory bound 是很重要的,因为这关系到我们优化程序时应该关注到的部分,比如对于 compute bound 程序,此时计算核心已经被占满了,但是内存带宽还未被充分利用,那么我们就应该想办法从算法的角度来减少不必要的运算,另一方面,对于 memory bound 程序,此时内存带宽已经饱和,计算量却不是很大,那么就需要考虑优化内存的读写策略。
通过算术强度这一指标,我们可以相对地估计某个算法是偏向计算密集还是内存密集的,比如某个算法的 AI = 1 FLOP/byte,这个数值是比较小的,但是在没有特定硬件信息的情况下还不足以判断是否是 compute bound。对于 A100 PCIe 40GB GPU 来说,它的 FP32 算力为 19500 GFLOPS,显存带宽为 1555 GB/s,在跑满带宽的情况下,运算吞吐量只有 1 FLOP/byte x 1555 GB/s = 1555 GFLOPS,这个数值明显小于理论计算性能,因此是 memory bound 的。对于其他算术强度,我们也可以通过类似的方法来判断,并总结出在跑满带宽的情况下算术强度和运算吞吐量之间的关系如下
其中,$CT$ 表示计算吞吐量,$AI$ 表示算术强度,$BW$ 表示内存带宽。但运算吞吐量并不是随着算术强度的增长而无限增长的,它始终受限于硬件的理论极限算力 $P$,也就是说上式还需要修正为
\[CT = min(AI \times BW, P)\]把上式用图形表示出来,可以看到一个类似屋顶形状的线,这就是 Roofline 模型
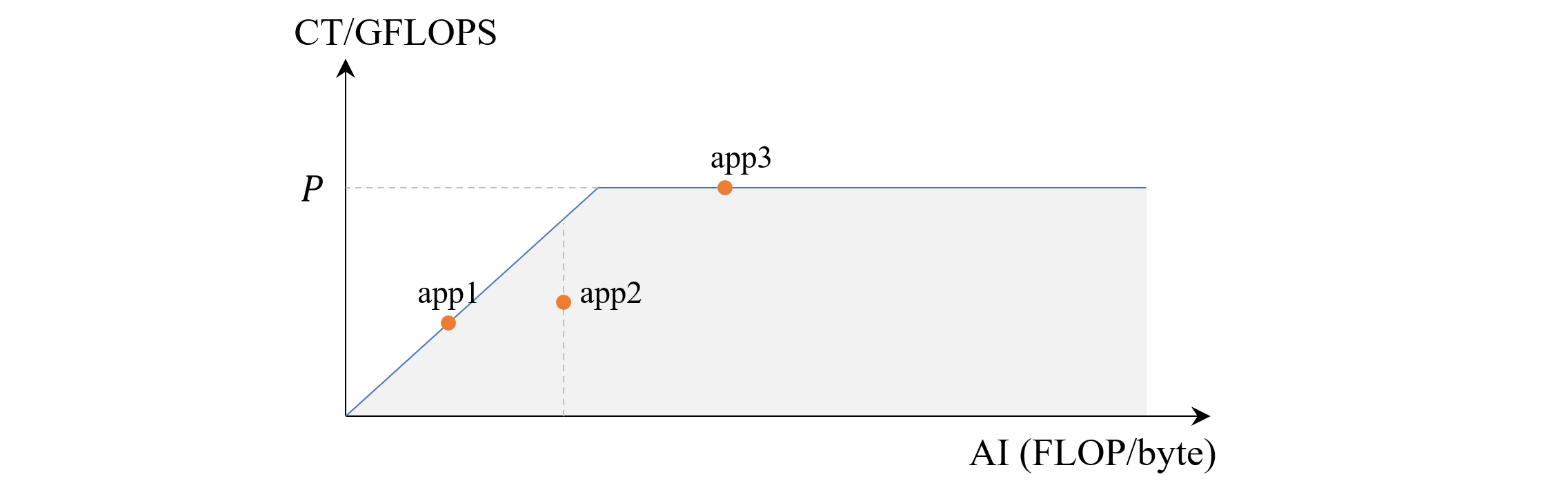
通过 Roofline 模型,我们可以比较直观地判断程序的性能特点,从而针对性的优化。比如上图中的 app1,在其所在的算术强度下,运算吞吐量已达到最大值,已经没有提升的余地了,同理的还有 app3,只不过它的算术强度已经达到了 compute bound 条件。而对于 app2,此时还可以通过优化内存读写策略来提升运算吞吐量。可以看到,roofline 模型为我们提供了一个非常便捷的工具来直观地评估程序在特定硬件上的性能表现。
参考
[1] How to Implement Performance Metrics in CUDA C/C++
[2] Roofline Model与深度学习模型的性能分析
[3] Roofline model