命名实体识别算法的原理与实现
命名实体识别(NER)是 NLP 里面的一项任务,它的目的是识别出自然语言中我们感兴趣的词语类型,比如人名、地名、数值以及其他专有名词等等,本质上是一种分类算法。
从形式上来看,NER 模型接收自然语句输入,输出每个词的类型,如下图所示
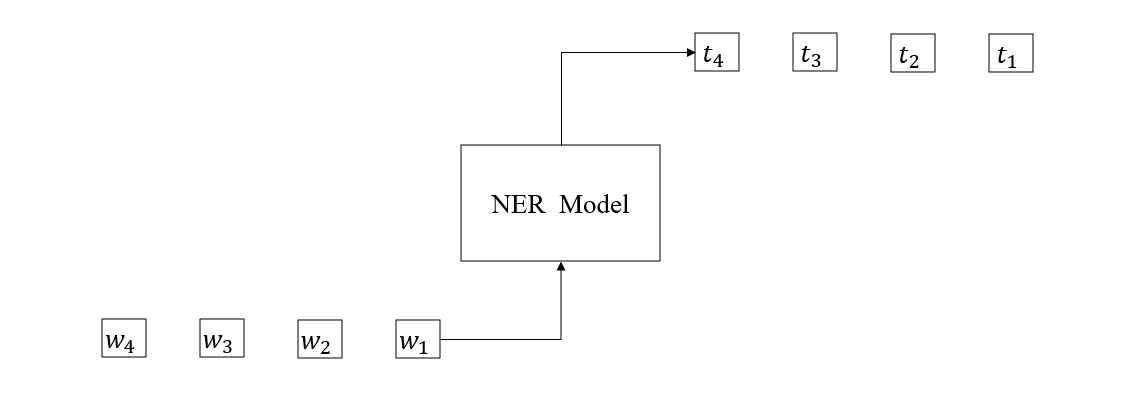
这里的 \(w_1, w_2 ..\) 等可以看作是 word id,\(t_1, t_2…\) 等可以看作是 tag id。而 NER 模型就是一个接收序列化输入的黑箱,它的结构可以是 RNN、LSTM、Transformer 以及各种 Bert。本文将分别使用 LSTM 和 Bert 来展示如何构造 NER 任务的训练框架。
数据集格式说明
NER 任务常用的数据格式一般有 BIO,BIOES 和 BMES,这里我们以最简单的 BIO 为例,B(begin)表示实体的开始,I(inside)表示实体成员,O(outside) 表示不属于任何实体。举个例子如下
source: 人 民 网 1 月 1 日 讯 据 《 纽 约 时 报 》 报 道 , 美 国 华 尔 街 股 市 在 2 0 1 3 年 的 最 后 一 天 继 续 上 涨 , 和 全 球 股 市 一 样 , 都 以 最 高 纪 录 或 接 近 最 高 纪 录 结 束 本 年 的 交 易 。
target: B_PER I_PER I_PER O O O O B_T I_T O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O B_T I_T O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O B_LOC I_LOC O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O B_LOC I_LOC O O O O O O O O O O O O O O O O O O O O O
在每个 B I 后面跟随的标记就是该实体所在的类型,比如 B_T 表示这是 T(time) 实体的开始,I_T 表示这是 T 实体的成员。而这些标记字符是可以根据应用情况来自行设置的,比如 LOC 表示 location,P 表示 person 等等。
构建语料库以及数据加载
在提供了数据集之后,我们需要知道该数据集包括哪些字符和哪些实体类型,并建立它们与索引的映射关系,具体到我们上面提到的 BIO 格式,可以给出如下实现
def load_corpus(source_path: str, target_path: str):
sentences = []
word_dict = {}
with open(source_path, "r", encoding="utf-8") as f:
for line in f:
if line.strip() == "":
continue
words=line.split()
sentences.append(words)
for word in words:
word_dict[word] = 1
sentence_tags = []
tag_dict = {}
with open(target_path, "r", encoding="utf-8") as f:
for line in f:
tags = line.split()
sentence_tags.append(tags)
for tag in tags:
tag_dict[tag] = 1
word2id = dict([(word, i) for i, word in enumerate(set(word_dict))])
tag2id = dict([(tag, i) for i, tag in enumerate(set(tag_dict))])
## assert equal
for words, tags in zip(sentences, sentence_tags):
assert(len(words) == len(tags))
return sentences, sentence_tags, word2id, tag2id
为了将这些语句输入到神经网络模型,需要将其转换成数字形式,一个最简单的方式是用它们的 id 来表示
inputs_ids = [[word2id[word] for word in sentence] for sentence in sentences]
tags_ids = [[tag2id[tag] for tag in tags] for tags in sentence_tags]
另一方面,我们知道,一个 batch 里面的语句往往长短不一,为了把它们放到一个 tensor 里面,我们把需要不足长度的句子进行补齐,这里我们借用 keras.preprocessing 包的 pad_sequence 方法
MAX_LEN = 100
sentence_lengths = np.array([min(len(words), MAX_LEN) for words in sentences]) ## 记录每个句子的原始长度
word2id["<pad>"] = len(word2id)
WORD_PAD = word2id["<pad>"]
tag2id["<pad>"] = len(tag2id)
TAG_PAD = tag2id["<pad>"]
padded_inputs_ids = pad_sequences(inputs_ids, maxlen = MAX_LEN, dtype="long", value=WORD_PAD, truncating="post", padding="post")
padded_tags_ids = pad_sequences(tags_ids, maxlen=MAX_LEN, dtype="long", value=TAG_PAD, truncating="post", padding="post")
接下来将数据分为训练集和测试集,并转换成张量类型
seed= 123
test_size=0.1
train_inputs, val_inputs, train_tags, val_tags = train_test_split(padded_inputs_ids, padded_tags_ids, test_size=test_size, random_state=seed)
train_lengths, val_lengths = train_test_split(sentence_lengths, test_size=test_size, random_state=seed)
train_inputs = torch.LongTensor(train_inputs)
val_inputs = torch.LongTensor(val_inputs)
train_tags = torch.LongTensor(train_tags)
val_tags = torch.LongTensor(val_tags)
train_lengths = torch.IntTensor(train_lengths)
val_lengths = torch.IntTensor(val_lengths)
然后我们再借用 pytorch 的 TensorDataset 来构造数据加载器(这样就不用我们自己实现 Dataset 了)
batch_size=4
trainset = TensorDataset(train_inputs, train_tags, train_lengths)
valset = TensorDataset(val_inputs, val_tags, val_lengths)
trainloader = DataLoader(trainset, batch_size=batch_size, sampler = RandomSampler(trainset))
valloader = DataLoader(valset, batch_size=2, sampler = SequentialSampler(valset))
基于双向 LSTM 的 NER 模型实现
我们这里的 NER 神经网络结构简单地说只有三个部分,首先是 embedding 层,它将字符id 嵌入到高维空间,然后是双向 LSTM 模块,它负责最重要的参数学习过程,最后是一个分类层,它负责将每个字符映射到正确的实体类别,整个模型结构如下如所示
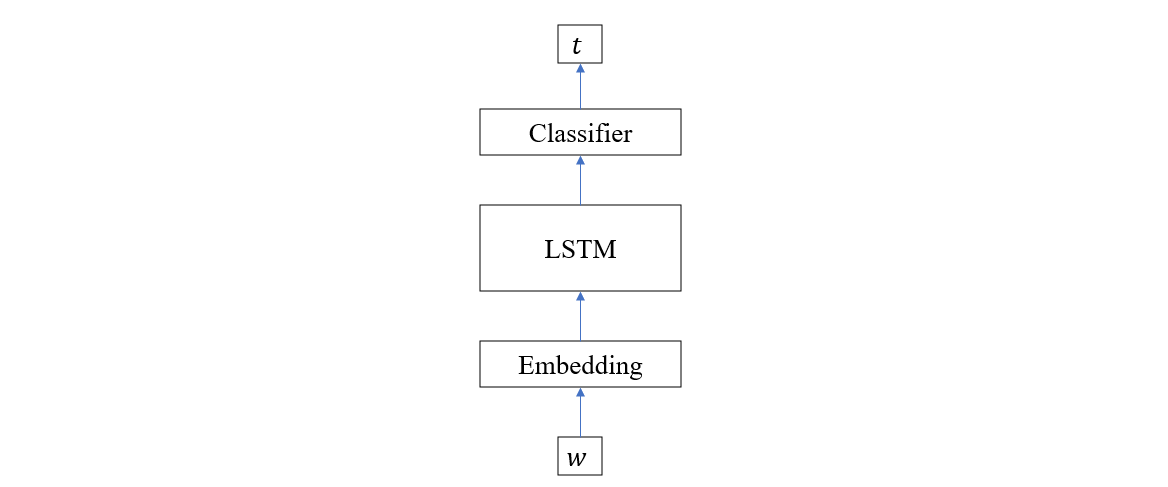
代码结构如下
class BiLSTM(torch.nn.Module):
def __init__(self, vocab_size: int, embedding_dim: int, hidden_size: int, tag_size: int):
'''
Args:
vocab_size: 词典长度
embedding_dim: 词向量嵌入维度
hidden_size: 隐层维度
tag_size: 标签数量
'''
super(BiLSTM, self).__init__()
self.embedding = torch.nn.Embedding(vocab_size, embedding_dim)
self.bilstm = torch.nn.LSTM(input_size=embedding_dim, hidden_size=hidden_size, batch_first=True, bidirectional=True)
self.fc = torch.nn.Linear(2 * hidden_size, tag_size)
self.tag_size=tag_size
def forward(self, x: torch.Tensor, lengths: list):
B, L = x.shape
emb = self.embedding(x) ## B x L x embedding_dim
packed = pack_padded_sequence(emb, lengths, enforce_sorted=False, batch_first=True)
out, _ = self.bilstm(packed)
out, _ = pad_packed_sequence(out, batch_first=True)
out = self.fc(out)
_, l, _ = out.shape
padded_out=torch.zeros([B, L, self.tag_size]).to(out.device)
padded_out[0:B, 0:l, 0: self.tag_size] = out
return padded_out ## B x L x tag_size
注意这里的 forward 方法,在输入 lstm 模块之前,我们使用 pack_padded_sequence 方法来包装张量,该方法的作用简单来说是让后续模型能够识别输入张量的哪些部分是 pad 的(即前面我们为了凑长度而填充的部分),这些 pad 值本身没有有用的信息,在张量计算的时候可以忽略,从而节省可观的计算量,具体可以参考 StackOverflow 的这个讨论。而经过 pad_packed_sequence 方法后,输出张量的语句长度是当前批次语句的最大长度,为了能匹配之前的填充长度,我们对其进行了扩展。
损失的定义和实现
由于 NER 任务本质上是一个分类问题,所以,这里我们就直接选择交叉熵损失函数,一个值得注意的细节是需要对填充部分进行排除,不让这些值参与到损失计算中来。
def loss_fun(outputs: torch.Tensor, targets: torch.Tensor, PAD: int) -> torch.Tensor:
'''
Args:
outputs: 模型输出张量 B x L x tag_size
targets: GT 张量 B x L
'''
mask = (targets != PAD) ## 对填充部分建立遮罩
targets = targets[mask]
out_size = outputs.size(2)
outputs = outputs.masked_select(
mask.unsqueeze(2).expand(-1, -1, out_size)
).contiguous().view(-1, out_size)
assert outputs.size(0) == targets.size(0)
loss = F.cross_entropy(outputs, targets)
return loss
训练过程
训练代码没什么好说的,按照 pytorch 标准套路来就可以了
device = "cuda:0" if torch.cuda.is_available() else "cpu"
vocab_size = len(word2id)
embedding_dim = 128
hidden_size = 128
tag_size = len(tag2id)
model = BiLSTM2(vocab_size=vocab_size, embedding_dim=embedding_dim, hidden_size=hidden_size, tag_size=tag_size)
model.to(device)
criterion = loss_fun
optimizer = optim.Adam(params = model.parameters(), lr = 0.001)
def train_step(model: BiLSTM, criterion, optimizer: optim.Optimizer, x: torch.Tensor, lengths: torch.Tensor, targets: torch.Tensor):
model.zero_grad()
outputs = model(x, lengths)
loss = criterion(outputs, targets, WORD_PAD)
loss.backward()
optimizer.step()
return loss.item()
def train_epoch(epoch: int, model: BiLSTM, criterion, optimizer, trainloader: DataLoader, print_step: int):
model.train()
total_loss = 0.0
total_step = len(trainloader)
for i, batch in enumerate(trainloader):
inputs, targets, lengths = tuple(t.to(device) for t in batch)
loss = train_step(model, criterion, optimizer, inputs, lengths, targets)
total_loss += loss
if (i + 1) % print_step == 0:
print(f"Epoch: {epoch}, step: {i}/{total_step}, loss: {loss}")
print(f"Epoch: {epoch}, average loss: {total_loss / total_step}")
def validate(epoch: int, model: BiLSTM, criterion, valloader: DataLoader):
model.eval()
total_loss = 0.0
for i, batch in enumerate(valloader):
inputs, targets, lengths = tuple(t.to(device) for t in batch)
with torch.no_grad():
outputs = model(inputs, lengths)
loss = criterion(outputs, targets, WORD_PAD)
total_loss += loss
print(f"Epoch: {epoch}, validate loss: {total_loss / len(valloader)}")
nEpoch = 3
print_step = 10
for epoch in range(nEpoch):
train_epoch(epoch, model, criterion, optimizer, trainloader, print_step)
validate(epoch, model, criterion, valloader)
torch.save(model, f"/checkpoints/NER-LSTM-epoch_{epoch}.pt")
基于 Bert 的 NER 模型
同 LSTM 类似,Bert 模型接收序列输入,并输出字符的高维 representation,这是每个字符在高维空间的特征表示,只需要在此基础之上加一个分类层即可,这里我们借用 huggingface transformers 框架的 BertForTokenClassification 来训练模型(这里的 bert-base-chinese 是中文bert的预训练模型,在只输入名称时它会自动下载,当然也可以在这里手动下载,然后输入模型路径即可)
device="cuda" if torch.cuda.is_available() else "cpu"
model = BertForTokenClassification.from_pretrained("bert-base-chinese", num_labels=len(tag2id), output_attentions=False, output_hidden_states=False)
model=model.to(device)
它的结构如下
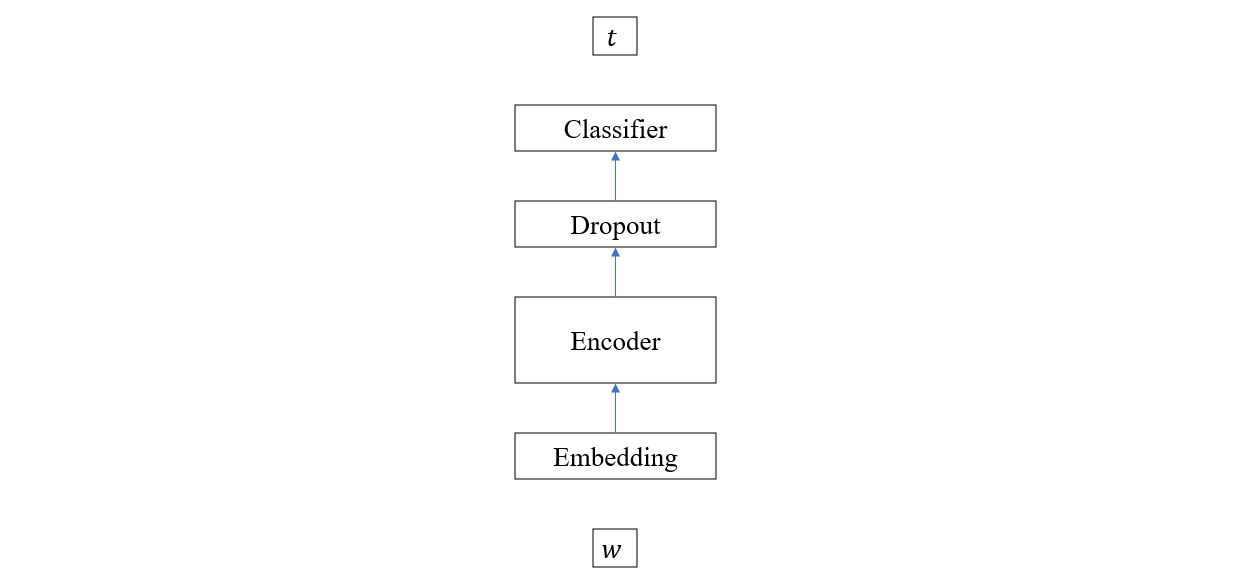
可以看到这与基于 LSTM 的 NER 模型几乎是一模一样的,所以前面的数据处理情况在这里也适用,唯一的不同是由于框架的原因,这里不用我们在模型中处理填充,只需把遮罩信息传给模型即可
## 为填充元素创建掩蔽列表
attention_masks = [[float(i != WORD_PAD) for i in inputs] for inputs in padded_inputs_ids]
train_masks, val_masks = train_test_split(attention_masks, test_size=0.1, random_state=123)
train_masks = torch.tensor(train_masks)
val_masks = torch.tensor(val_masks)
并且该模型也自动计算了损失,我们直接取出来即可
outputs = model(inputs_ids, attention_mask=masks, labels=tags)
loss=outputs.loss
其余过程与前面类似,这里就不赘述了。
总结
本文介绍了 NER 任务的基本概念,并在代码层面分别介绍了如何基于 LSTM 和 Bert 来搭建 NER 模型,当然还有很多细节需要在实际训练过程中修改。
参考文章列表:
- https://zhuanlan.zhihu.com/p/61227299
- https://www.depends-on-the-definition.com/named-entity-recognition-with-bert/