关于 Faster RCNN 目标检测算法的详细分析
追本溯源
Faster RCNN 的最初版本是 RCNN,这是将神经网络算法应用在目标检测领域的最初的尝试之一,因此其方法显得有些稚嫩,或者说更易于理解接受。RCNN 的全称是 Regions with CNN features,简单来说,RCNN 的原理是用 CNN 来提取 Region 的特征,然后将这些特征送入分类模型进行分类,当时比较流行的分类模型还是像SVM这种比较传统的算法,为什么会说 RCNN 是两阶段的模型,就是因为最开始特征提取和分类模型都不统一,模型的训练过程不是连续的。
前面我们提到 Region 这个词,如果不解释一下的话可能会引起迷惑。其实 Region 就是图片中的一块区域,因为目标检测模型和LeNet、VGG这些分类模型不一样,其目的是为了检测图片中的对象,换句话说,是为了对图片中的一块区域进行分类,粗暴点讲,如果我们密集的从图片中提取大量Region,然后送入分类模型,总会出现某个区域刚好包含需要被检测对象的情况,这样一来它就会被检测出来。
但是,人们显然没有这么傻,一张图片中的Region有无数个,靠暴力枚举明显不现实。因此有专门的算法用来确定可能存在目标的Region,不用很精确,只需要排除明显的负样本就可以了,这样的算法过程就被称为 Region Proposal。在 RCNN 里面,Region Proposal 算法叫 Selective Search,这是一种传统的图像处理算法,效果比较一般,在当时也用够了。
有了以上这些概念之后,下面这张图就比较容易理解了
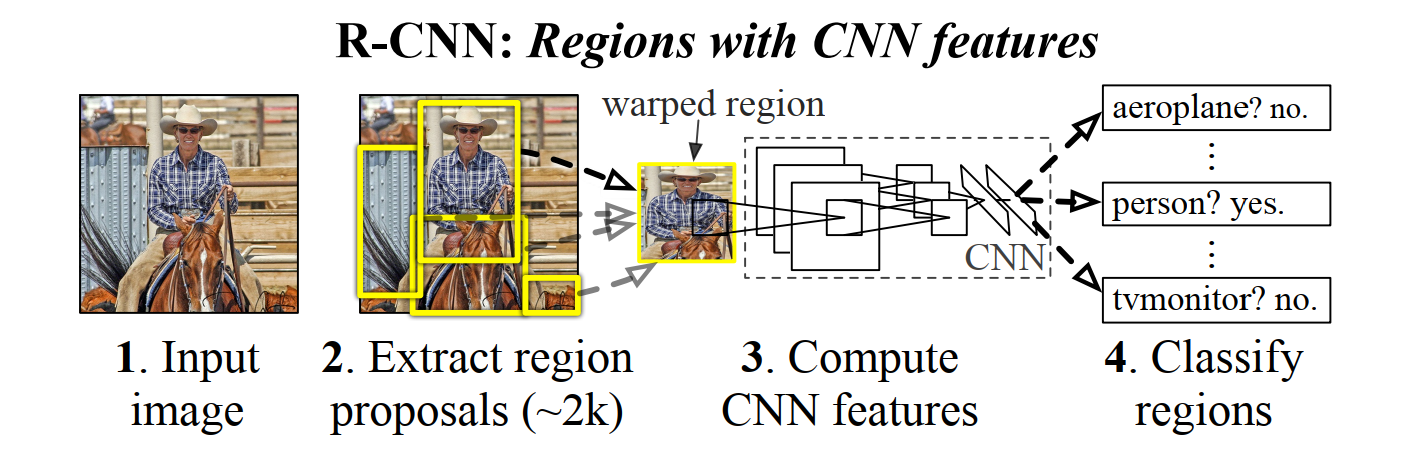
这里第2张图里面的黄框框就是 Region Proposal 算法给出的 Region,这里直接将其剪切出来,需要缩放到固定尺寸,之所以这样做,是因为卷积网络的输出尺寸依赖于输入的图片尺寸,既然后面需要将提取的特征送入 SVM 分类器,那么所有特征的维度必须是相同的,于是要求输入图片的尺寸是固定的。
需要提到的是,RCNN 使用 backbone 是类似 VGG 这种分类网络,只需要在训练集上对预训练模型进行 fine-tuning,分类器单独训练,而不是像后来的目标检测模型需要 end-to-end 的训练。
融合增强
RCNN 将卷积神经网络应用于对象检测任务,是具有开创性的工作,但也存在几个明显的缺陷。首先是对于 Proposal Region 的非比例形变处理有可能使得提取的特征不准确,会影响分类模型的效果。第二个不足是每个 Proposal Region 都会被送入卷积网络中进行计算,一张图里面大约有2000个 Region,它们相互重叠,如果把每个 Region 都输入卷积网络中,必然有许多冗余的计算,可见这效率并不高。
针对第一个问题,SPPNet 提出了一个新的结构,称为空间金字塔池化(Spatial Pyramid Pooling)。利用 SPP,可以允许卷积网络输出不同尺寸的特征图,具体原理如下图
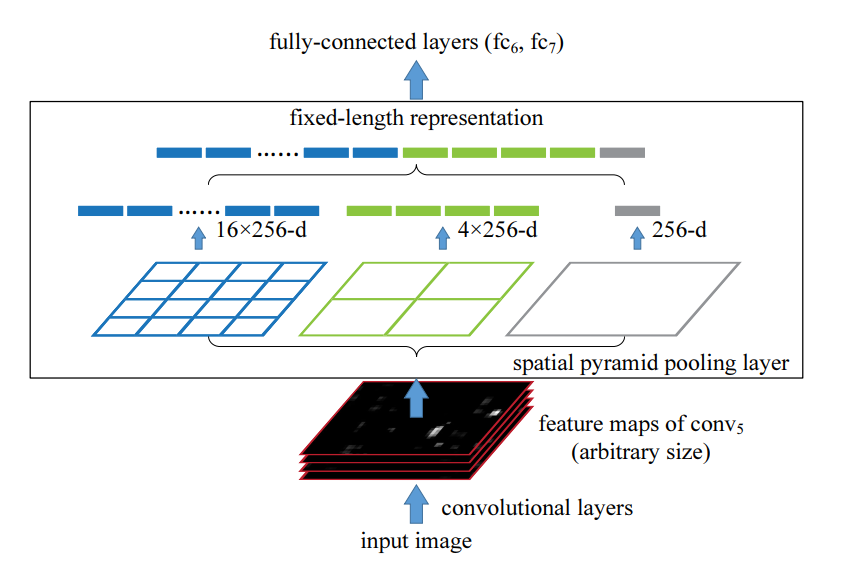
输入图片经过 backbone 后,输出尺寸为 \(m\times n\times d\) 的特征图,其中 \(m,n\) 可以是任意的,依赖于输入图片的尺寸,而 \(d\) 是固定值,这与卷积网络的设置相关,在图中为 256。然后特征图分三路池化,最左边的的 kernel_size 为 \(\left(\frac m 4, \frac n 4\right)\),中间的 kernel_size 为 \(\left(\frac m 2, \frac n 2\right)\),最右边的 kernel_size 为 \((m, n)\),于是左路输出为 \(4\times 4 \times 256\),中路输出为 \(2 \times 2 \times 256\),右路输出为 \(1 \times 1 \times 256\)。可见,这时的输出与特征图尺寸 \(m, n\) 没有一毛钱关系了,将这些输出堆叠成 1 维向量,后续接全连接层即可继续传播。这就是 SPP 层达到的效果,根据原论文的实验,对于多种cv任务,由 SPP 层改造的网络都能取得比原先更好的效果。
很自然地,在 R-CNN 的后续版本 Fast R-CNN 中,借鉴了 SPPNet 的思想,只不过经过简化改造后,摇身一变成为了 ROI Pooling。简单的讲,ROI Pooling 仅仅使用了 SPP 中的一路池化,而不是多路池化,另外一个区别是 ROI Pooling 的应用范围不是整张特征图,而是图中的一个 Region,这个 Region 的产生与 Fast R-CNN 的另一个改进有关,我们接下来叙述这个事情。
前面提到,在 R-CNN 中, 一张图片的每个 Proposal Region 都会被送入卷积网络计算一次,因此产生了大量冗余运算量,针对这一缺陷,Fast R-CNN 调整了计算顺序,首先由 selective search 生成 Proposal Region,并将其记录下来,然后将整张图片送入卷积网络,提取的特征图相对于原图来讲是缩小了的,这时再计算之前的 Proposal Region 在特征图上的相对位置,这时的区域又被称为 ROI (region of interest),在这个区域上的池化就被称为 ROI Pooling。
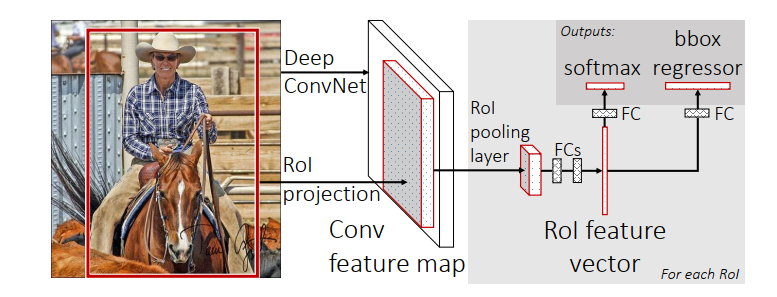
从上图 Fast R-CNN 的架构还可以看到,最后的分类器被换成了 softmax 层,这样就可以 end-to-end 训练了。除此之外,从 ROI 提取的特征被同时送入了 softmax 分类层和 bbox 回归层,这是一个典型的多任务训练模型,网络的损失函数由两部分损失共同组成。
完全体
经由 R-CNN 的开创性研究,以及融合了 SPPNet 的增强型 Fast R-CNN,还剩下 Selective Search 这个唯一的旧时代产物。既然一切都是神经网络,那为何 Region Proposal 不能用神经网络来提供呢?基于这样的疑惑,RPN 诞生了。RPN 是 Region Proposal Network 的缩写,其输入是任意尺寸的特征图,输出是一系列的 Region。
Faster R-CNN 相对于前代 Fast R-CNN 的最重要改进就是用 RPN 取代了 Seletive Search 来提供候选 Region,网络架构图如下
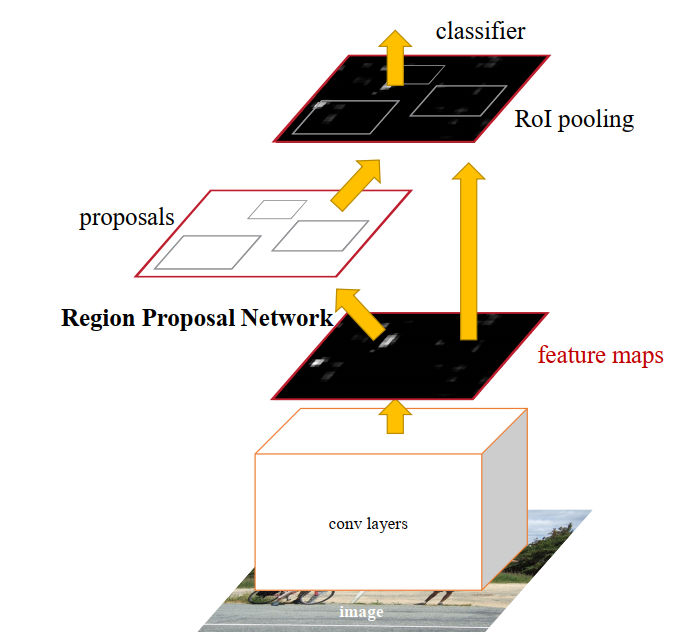
经过卷积网络 (也被称为 backbone) 之后,数据分两路而上,如果只看右边的结构,可以发现其与 Fast R-CNN 完全一致。左路的 Region Proposal Network 看起来只有一层,但它实际上确实是一个网络,有输入(feature maps),有输出(proposals),而且与前面的卷积网络共同组成了一个可训练的网络。是的,Faster R-CNN 的训练分为两个阶段,第一阶段利用现成的卷积网络 (比如resnet) 以及其预训练模型,训练 RPN 网络的参数,这一阶段 ROI Pooling 层及其后续部分不参与。第二阶段才训练检测模型,这一过程同 Fast R-CNN 是一样的,只不过 ROI 是由上一步训练好的 RPN 提供的,从而摆脱了对 Selective Search 的依赖。
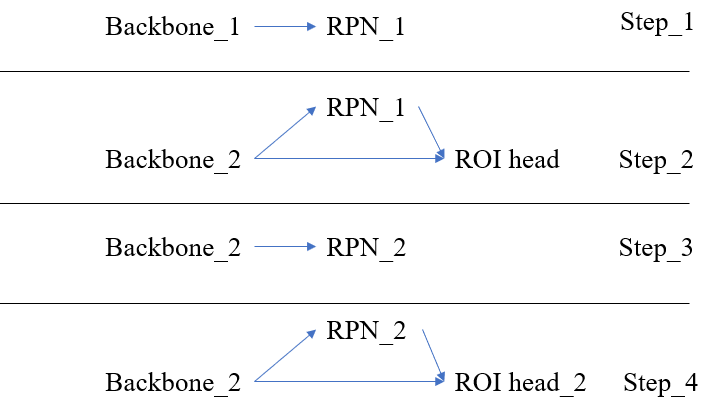
在原论文中,作者的训练方法更为细致一点,将上面两个阶段重复了两次,共有四步,具体如下:
- 利用预训练 backbone 模型训练 RPN 网络,得到 fine-tuning 后的参数 backbone_1 以及 RPN_1;
- 利用预训练 backbone 模型和第一步的 RPN_1 训练检测模型,此时 RPN_1 不变,得到 backbone_2 和 ROI_head_1;
- 利用 backbone_2 和 RPN_1 进行 fine tuning,此时固定 backbone_2,得到 RPN_2;
- 利用 backbone_2 和 RPN_2 训练整个网络,此时固定 backbone_2 和 RPN_2,得到 ROI_head_2。
经过以上四步,得到参数 backbone_2,RPN_2 和 ROI_head_2 便构成了整个模型的参数,如果文字描述不太清楚,可以参考下图所示的步骤
RPN
从整体视角看完 Faster R-CNN 的结构之后,我们来独立分析一下 RPN 的结构。根据前面的叙述,我们知道,RPN 的输入是 backbone 的输出特征图,RPN 的输出是 Region Proposal,也就是可能包含物体的区域。为了说明 RPN 是原理,我们先来看一下 backbone 的输出与原图之间的关系
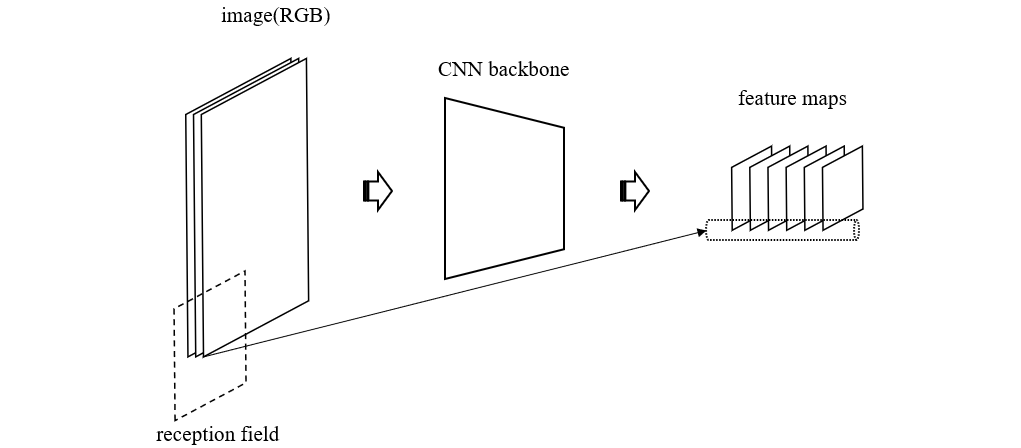
可见,输出特征图中的每个像素对应于原图中的一个区域,也就是我们常说的感受野 (reception field),于是多张特征图上的相同位置的值组成的向量就是对应感受野的特征向量,里面的信息就有该区域物体的特征(如果有的话)。而 RPN 的真正作用就是将这些信息解码出来,RPN 的第一层仍然是一个卷积层,kernel_size 为 \(3\times 3\),它的作用是进一步减小特征图的尺寸,然后特征图分两路行进,第一路进入一个输出通道为 \(2k\) 的 \(1\times 1\) 卷积层,其目的是计算特征图每个点所对应的感受野是否含有物体(具体是哪类物体这里还不明确),第二路进入一个输出通道为 \(4k\) 的 \(1\times 1\)卷积层,其目的是计算特征图每个点对应的感受野的物体边界框 (bbox),所以第一路卷积层被称为分类层,第二路卷积层被称为回归层。如下图所示
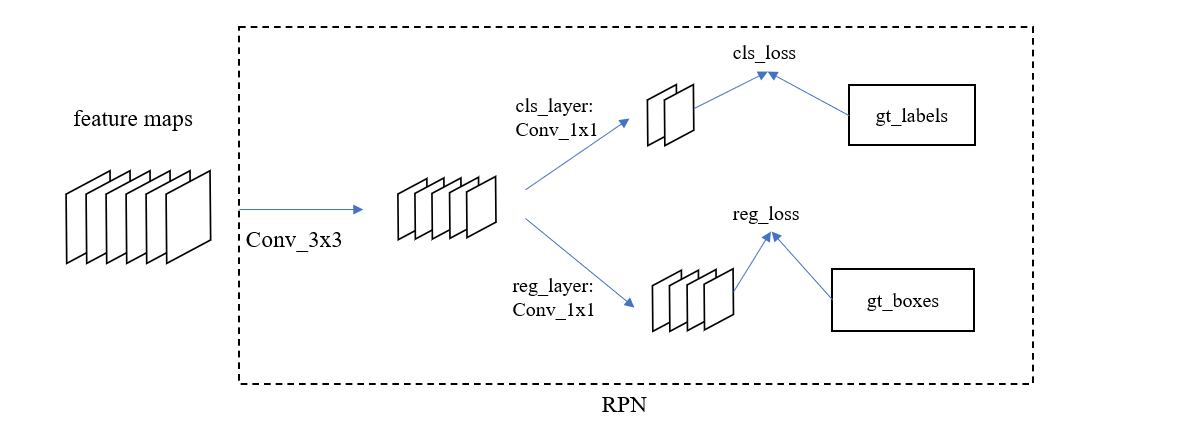
现在来解释前面提到的 \(k\) 的含义,前面我们提到特征图上的点对应于原图上的一个区域,多个特征图的相同位置上的值组成的向量是这个区域的特征向量,它具备该区域物体的特征。如果我们简化一下 RPN,去掉 reg_layer, 只保留 cls_layer,当特征图上某个点(也就是它对应的感受野)被预测到含有物体时,则将其作为 Proposal Region 交给后续网络,那么此时 \(k = 1\),cls_layer 输出 2 个通道,分别表示有物体的概率和没有物体的概率。但这时存在一个很重要的问题,即后续网络在对 Bounding Box 做回归的时候,输入是一个很大的区域,而 Ground Truth 可能只是其中很小的一部分,这就要求回归模型必须有很强的非线性拟合能力,但这在几层简单的神经网络中是很难做到的,所以必须在 RPN 中就对 Proposal Region 做更精细的预测。
实现这种更精细的 Proposal Region 预测的方法其实就是预先定义锚框(Anchors),在上段设想的简化版 RPN 中,特征图的每个点对应原图中的一个区域,而这一次,我们让每个点对应 k 个区域,这 k 个区域就是所谓的 Anchors。这时 cls_layer 的输出通道为 2k,每两个通道预测一个锚框的物体包含/不包含概率,而 reg_layer 的输出通道为 4k,每 4 个通道预测物体相对于一个锚框的偏移。在后续网络中,只有被预测为含有物体的区域才被输出,对应的 Proposal Region 的坐标就为 锚框 + 偏移量。
由于锚框是自定义的,所以其设计具有很大的灵活性,同时也对模型的效果有很大的影响,在原论文中,作者使用了 3 个尺度以及 3 个高宽比的两两组合,对于特征图中的某个点来说,其对应的 anchors 集合在原图上的形状大致如下图
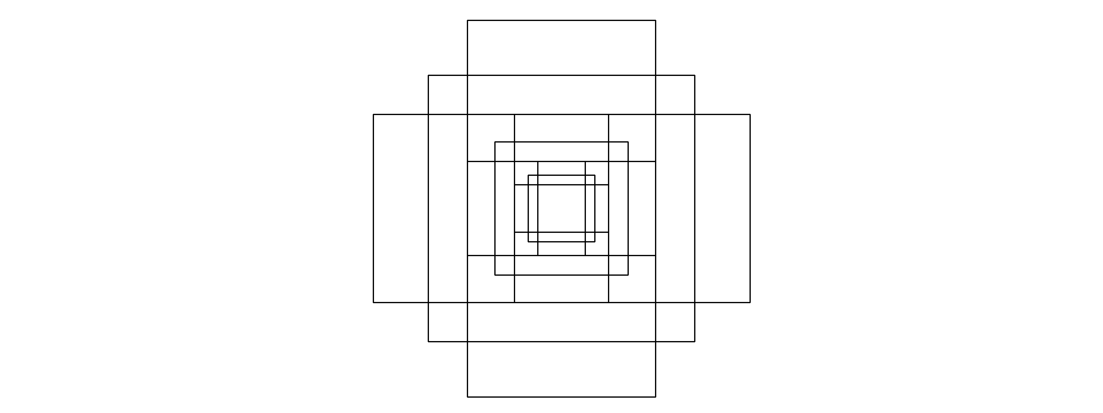
假设每个点上规划了 k 个 anchors,那么尺寸为 \(m\times n\) 的特征图总共会产生 \(mnk\) 个 anchors,它们中的大多数都和实际要检测的物体没有关系,RPN 就是要从中挑选出可能含有物体的 anchors,然后利用 reg_layer 计算的偏移量来 Proposal Region。
为了训练 RPN,显然需要设计针对这一任务的 Ground Truth,最开始的时候,我们得到的 Ground Truth 只是图像中的物体边界框坐标和类别标签,根据前面描述的 RPN 结构,cls_layer 的输出结构为 \(m\times n \times 2k\) 张量,如下图所示
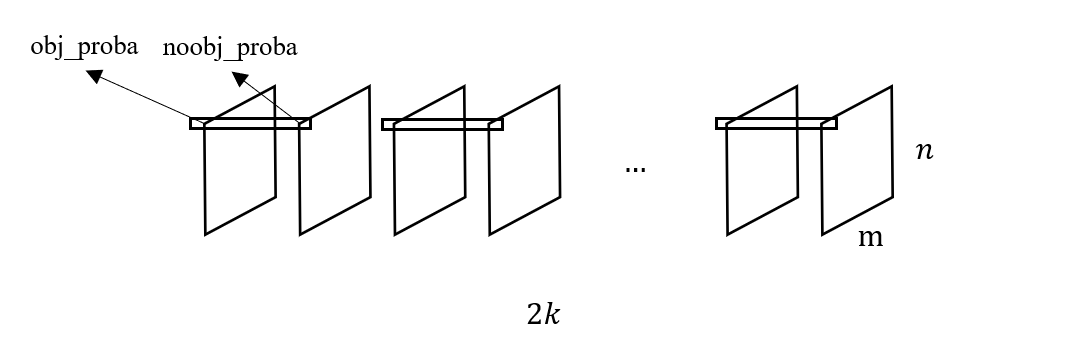
为了将 Ground Truth 变换成上面这种结构,需要观察 \(m\times n \times k\) 个 anchors 的物体包含情况,如果包含物体,则将对应位置的 obj_proba 设为 1,noobj_proba 设为 0,反之亦然。类似地,reg_layer 的输出结构如下图
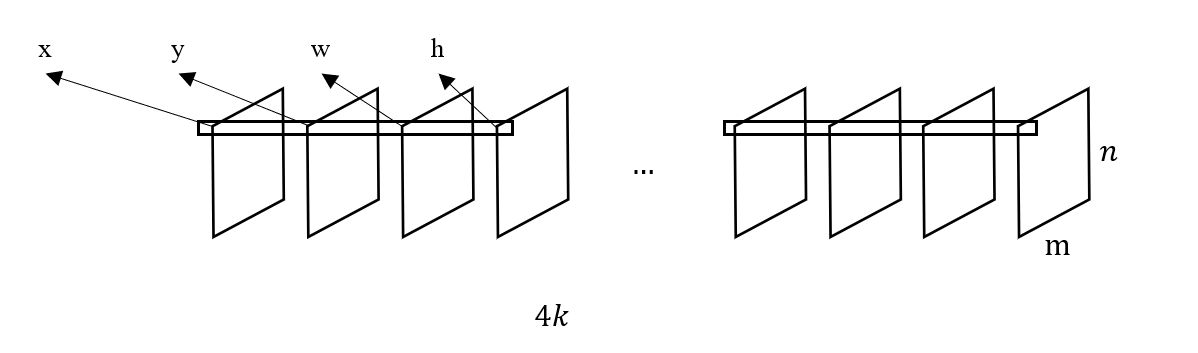
如果某个 anchor 包含物体,则将物体的边界框坐标填充到张量的对应位置,否则,不做任何处理。
接下来的问题是如何判断某个 anchor 包含某个物体,一种常用的方法是计算两个边界框的交并比(Intersection Over Union),也就是两个矩形交集的面积比上它们并集的面积,如果交并比大于某个阈值,则认为此 anchor 包含物体,如果小于某个阈值,则判断为负样本。这就要求 anchor 与物体的形状大小位置必须足够接近才能被判断为 Proposal Region,也就为后续网络的回归任务减轻了难度。对于其余的既不是正样本也不是负样本的 anchor,则不参与后续的损失计算。
最后,我们再讨论一下 RPN 的损失函数,由于分为分类和回归两个任务,所以损失函数也是两个任务的损失组合,定义如下
\[L = \frac 1 {N_{cls}} \sum_{i} L_{cls} (p_i, p^*_i) + \lambda \frac 1 {N_{reg}} \sum_{i} p_i^* L_{reg}(t_i, t^*_i)\]其中 \(N_{cls}, N_{reg}\) 分别是参与分类和回归损失计算的 anchor 数量,\(p_i\) 表示第 \(i\) 个 anchor 的物体预测概率,\(p_i^*\) 表示 gt,如果有物体,则为1,否则为0,\(t_i\) 和 \(t_i^*\) 则分别表示第 \(i\) 个 anchor 的边界框预测和 gt。值得注意的是,\(L_{reg}\) 的前面有一个 \(p_i^*\),这其实表示如果当前 anchor 中没有物体,那么不参与损失计算。\(\lambda\) 是调节分类和回归预测权重的超参数。\(L_{cls}\) 是交叉熵损失函数,\(L_{reg}\) 的定义如下
\[L_{reg} = \sum_{j \in \{x, y, w, h\}} smooth_{L_1}(t_{ij} - t_{ij}^*)\]其中
\[smooth_{L_1}(x) = \left\{ \begin{aligned} &0.5x^2 \quad |x| < 1\\ &|x| - 0.5 \quad otherwise \end{aligned} \right.\]ROI Pooling
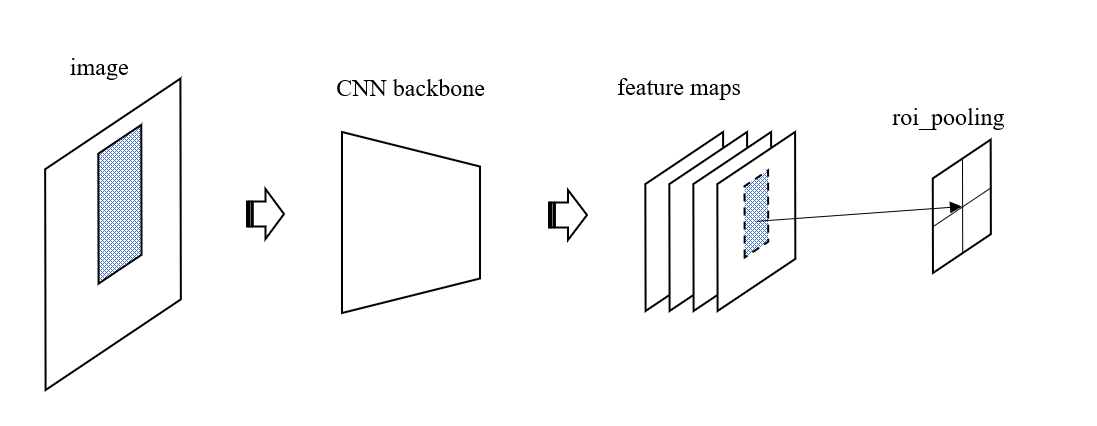
前面提到,图片经过骨架网络后输出特征图分两路传导,一路经过 RPN 产生了 Proposal Region,也就是大概率包含物体的区域,另一路直接抵达 ROI Pooling 层,ROI Pooling 层根据 RPN 提供的 Region 对特征图进行池化。需要说明的是,RPN 提供的 Region 坐标是在原图上的位置,原图和特征图的尺寸是不一样的,所以必须将这个 Region 投影到特征图上,如下图所示
然后我们再来看看这个 ROI Pooling 操作,在 Fast R-CNN 中,我们提到,ROI Pooling 是 SPP Layer 的简化版本,只有一路输出,通过事先定义的输出尺寸来进行最大化池化操作,具体如下图所示
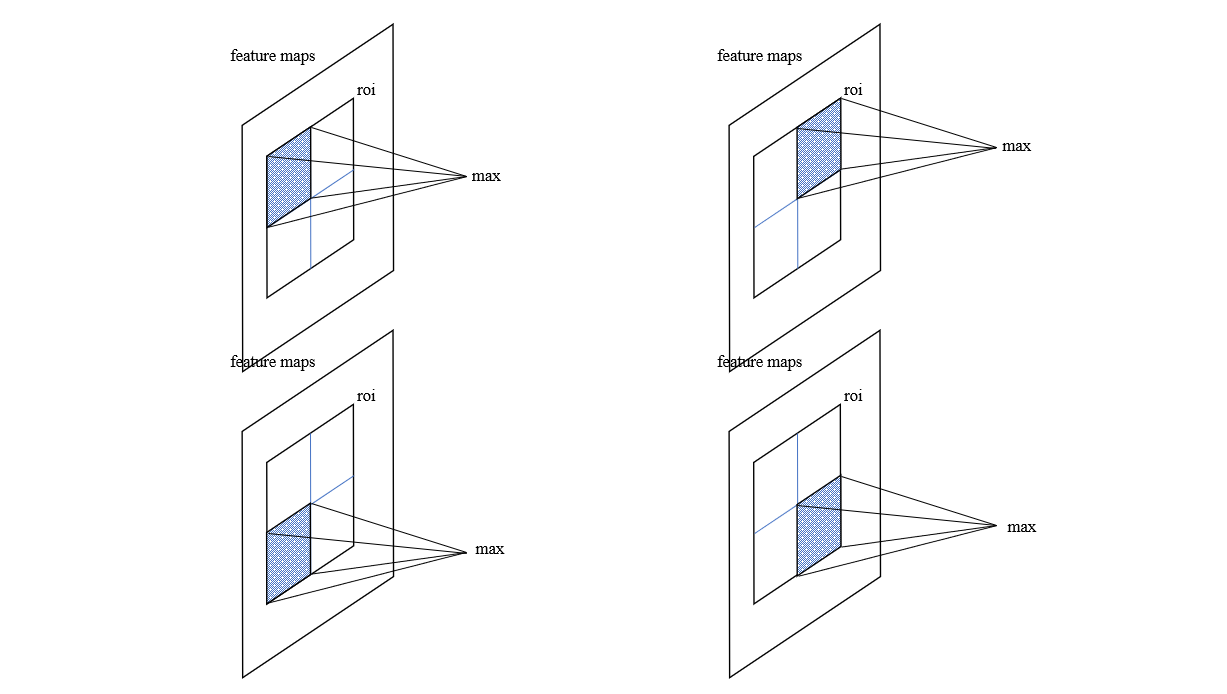
通过 ROI Pooling 层,无论多大的 ROI 区域都会生成相同尺寸的向量,后续再进入全连接层进行分类和边界框回归任务。
结语
通过本文,我们从最原始的 RCNNN, 到 Fast R-CNN ,再到 Faster R-CNN,逐步阐述了 R-CNN 系列目标检测架构的演化进程,其中 Fast R-CNN 主要引入了 ROI Pooling,并用 Softmax 代替 SVM 进行分类,实现了 end-to-end 训练,而 Faster R-CNN 则主要是引入了 RPN 代替 Selective Search 算法实现 Region Proposal。随着网络结构不断完善,其检测能力也不断提高,后续的发展也在不断进行,我们将在后面的文章中继续探讨。