使用 PyTorch 实现 yolov3 算法 (1)
在这一系列文章中,我们将使用 pytorch 框架来实现 yolov3 目标检测算法,在理解 yolo 系列算法的同时,也希望对 pytorch 框架有更深入的认识。
对于初学者来说,我觉得最先应该理解的还是目标检测这种任务的基本流程,而 yolo 原论文则不太适合新手直接去看。但是奇怪的是网上对 yolo 的介绍大都是对原论文的翻译,如果强行去啃,很容易就迷失在各种名词概念中无法自拔,所以我希望这篇对 yolo 的介绍能做到由浅入深,老少咸宜,不求面面俱到,但求写出来的东西都是容易被理解的。
首先,我们看神经网络这个东西,把它当成一个黑箱,我们从一端输入特征,另一端输出计算结果。对于分类问题,输出端给出的是一个向量,向量维度等于类别数量,每个元素表示对应类别的置信度。对于回归问题也类似,只不过输出的是需要拟合的值。而目标检测问题的输出则稍微复杂一点,输入一张图片,我们希望给出图片中物体的种类和坐标位置。通常来说,可以使用向量来表示种类,就像分类问题那样,而物体的位置则可以用矩形边界框的位置和大小表示,把这些值排列起来又是一个向量。
\[[x, y, w, h]\]当然,为了存储的方便,还可以把用于分类的向量合并起来,得到一个更大的向量
\[[c_1, c_2, c_3, ... c_n, x, y, w, h]\]通过这个向量,我们便能得到图片中一个物体的类别和具体位置。但是,一般情况下,一张图片肯定不止一个需要检测的对象,在具有多个物体情况下如何对输出数据进行组织就是一个相当关键的问题,我个人认为这也是理解 yolo 前至关重要的概念。如果我们仍然简单的把多个向量在长度方向上堆叠,那么不同物体数量的图片,其输出向量的长度也不同,这在神经网络中显然不好实现。那么把这些向量在另一个维度上排列呢?也就是像下面这样的矩阵形式
\[\left[ \begin{aligned} c_1^1 &\quad c_2^1&\quad ... &\quad x^1 \quad y^1 \quad w^1 \quad h^1\\ c_1^2 &\quad c_2^2&\quad ... &\quad x^2 \quad y^1 \quad w^1 \quad h^1\\ ...\\ c_1^n &\quad c_2^n&\quad ... &\quad x^n \quad y^n \quad w^1 \quad h^1 \end{aligned} \right]\]这种形式有效缩短了输出向量的维度,但还是存在不同数量物体导致输出矩阵大小不同的问题。其实,无论怎样排列,只要我们使用一个固定长度的向量来表示一个物体,就都会遇到这样的问题。那么怎样才能避免呢?一个可行的方案是固定物体的上限,也就是说输出固定维度的矩阵,假如矩阵的维度大于实际的物体数量,那么将超出的部分用 0 来填充,在预测的时候,如果我们发现所有类别上的置信度都极其接近于 0 ,也就知道这个位置上没有任何物体。
但事实上,很少有神经网络只输出一个矩阵,对于最后一层是全连接层的神经网络来说,它输出一个向量,而对于全卷积神经网络来说,它输出的是由特征图堆叠而成的立体结构(也就是大家常说的张量,虽然张量有严格的定义,但是大家都这么用,所以这里也没什么问题了)。我们知道,卷积层使用多个卷积核对前一层的特征图做卷积运算,每一个卷积核都会输出一个特征图,于是卷积层的总输出便是多个特征图的堆叠。对于像 AlexNet,VGG 这样的用于简单分类的神经网络,在多层卷积之后接全连接层,这样就把卷积层提取的特征映射成图片属于各类别的置信度向量,从而完成对图片的分类。而全卷积神经网络的思路则更灵活,它同样可以用于图片的分类,而且是对图片中的多个元素进行分类,怎么做到的呢?这里我们复习一下图像的卷积
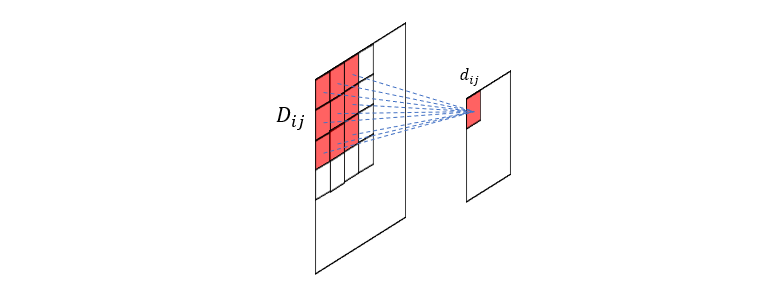
卷积的每一次运算都是把前一层的局部区域 \(D_{ij}\) 的像素值加权映射到后层的一个值 \(d_{ij}\),这里的 \(D_{ij}\) 又被称为 \(d_{ij}\) 的感受野 (Receptive Field),在卷积之后,图像的信息显然是损失了,\(d_{ij}\) 成为 \(D_{ij}\) 留下的“代表”,我们也可以将它称为特征,所有的局部区域的特征按原来的顺序排列便构成了特征图(为什么在这里加黑强调,因为我觉得这是 feature map 的最初含义所在)。虽然一次卷积使图像的信息下降了很多,但我们可以使用多个不同的卷积核对同一幅图像进行多次卷积,从而得到多幅特征图,由于不同的卷积核所提取到的特征不同,所以多幅特征图实际上使得原图像的信息损失变得不那么大了。
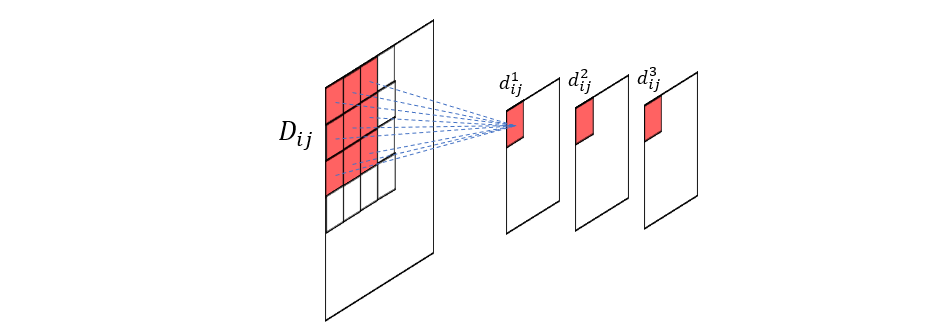
现在我们再来看局部区域 \(D_{ij}\) ,由于每个特征图都有一个 \(d_{ij}\),那么所有这些 \(d_{ij}\) 排在一起便可以组成 \(D_{ij}\) 的特征向量(也就是图上的 \(d_{ij}^1, d_{ij}^2, d_{ij}^3,…\))。从这个角度来看,卷积运算实际上是把图像的二维信息变换到三维结构中来了,付出的代价是部分信息的损失,当然这里面有可以说道的地方。在神经网络中,卷积核是通过不断的反向传播学习得到的,当合理设计的网络达到最优权重分布时,也就意味着卷积核提取的信息已经足够应用到当前的神经网络任务中来,而卷积所损失的信息则显得没那么重要了(这些信息也就是我们常说的冗余信息)。
其实有时候我们对卷积层、全连接层这些概念的区别讲述会带来一些困扰,如果将二维的图片按行扫描后排列成一维单元,就会看到,卷积层不过就是全连接层的一种特殊形式,它在某些连接上的权重始终为零而已。
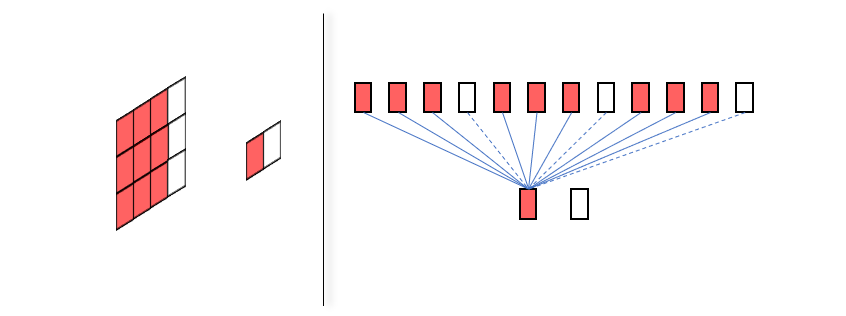
图中左边的卷积层和右边的全连接层是等价的,其中虚线表示权重为零,我们也看到,所谓的卷积核其实不过是相关权重的二维重排。
之所以提上面这一点,是因为这让我们更清楚的看到了卷积层相比全连接层到底做了什么,其实就是舍弃了前一层某些单元和后一层某些单元的连接,从二维图中可以发现舍弃的部分就是距离局部区域 \(D_{ij}\) 中心较远的像素。这也说明了,如果我们使用卷积层来做预测,那么就默认接受这样一个假设,那就是图像上相距较远的点具有更小的相关性。那么这个假设是否正确呢?我认为这得分情况讨论,比如一张图像是狗的面部特写,它的耳朵和鼻子相对来说是离得较远的区域,但是在分类问题中,两者的相关性却是很强的。所以在这个意义上来看传统的分类神经网络就很有意思了,它们使用的素材中物体基本上充满了整个图片,卷积层负责提取物体各部位的局部特征,但是在最后的分类任务中,已经不能忽略各个局部的关联性,于是所有局部特征都参与到下一层的每个神经元的计算,这刚好就是全连接层。
对卷积层进行了一番探讨之后,下面我们还是回到主题,看看全卷积神经网络如何应用到目标检测问题中来。由于全卷积网络没有全连接层,所以它的最终输出仍然是多个特征图的堆叠,看起来就是三维的数据立方体
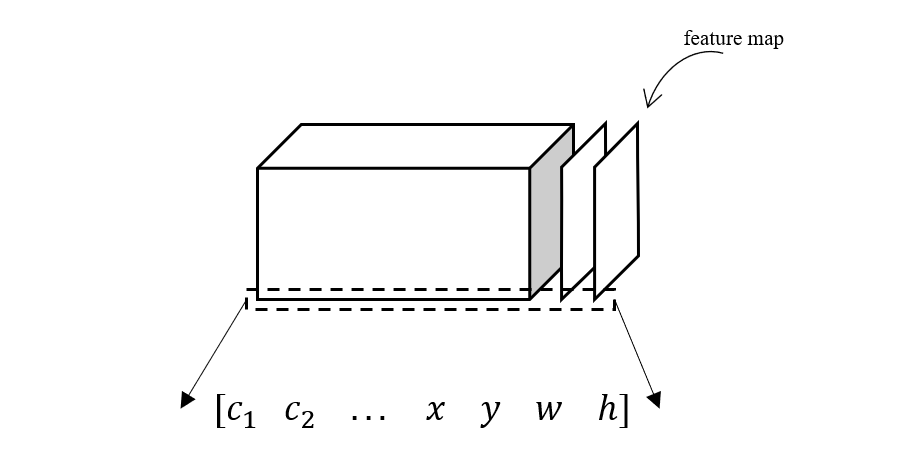
而在前面我们也看到,物体在图片中的表示形式可以是一个向量,包含了目标的类别、位置和大小这些量。我们也同样知道特征图上的每个点是它的感受野 \(D_{ij}\) 的特征,所有特征图上同样位置的点组成的向量便是原图上该局部区域的特征向量。于是我们可以把此特征向量当作目标的表示向量带入训练过程,这样一来就相当于把原图的局部区域映射成了目标的表示向量,所以最终我们的训练过程便是输入原图,经过一系列卷积变换后得到一组预测向量,其中每个向量都对应原图中一个区域包含某个物体的置信度和位置,最后再定义合适的损失函数进行误差的反向传播。
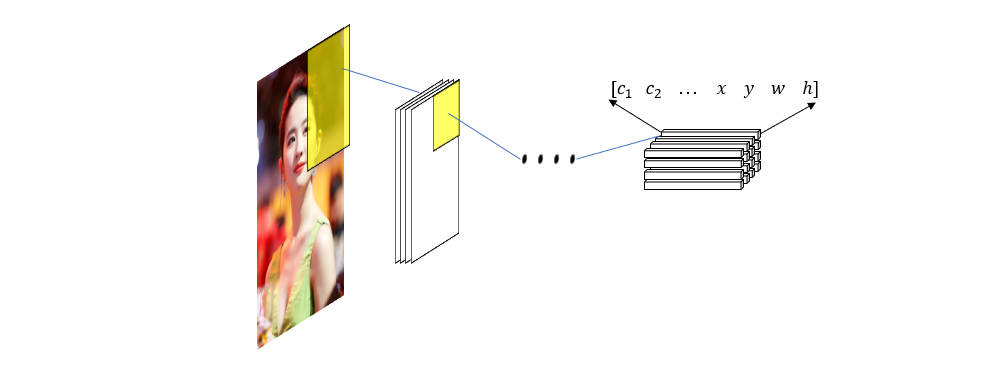
总结 本篇算是对目标检测究竟要怎样训练有了一个大致的陈述,我认为在正式学习之前有这样的概念是很重要的,否则看别人的文章都不知道人在讲啥,比如有人说 yolo 会先把图片分割成 13 x 13 的格子,再分别计算物体位于格子中的概率,如果事先不知道这些格子其实就是最终输出特征图上每个点的感受野,那么就根本不能理解所谓的把图片分成格子在神经网络中是怎样实现的。